
Accepted at ECCV 2026
MultiMem: Measuring and Mitigating Memorization
in Multi-Moda Contrastive Learning
Wenhao Wang1, Franziska Boenisch1, Michael Backes1, Adam Dziedzic1
1 CISPA Helmholtz Center for Information Security
On This Page
Overview · Why Multi-Modal? · How MultiMem Works · What Drives Memorization · Mitigation Strategies · Results · Why It Matters · Take-Aways · Citation
Overview
Multi-modal contrastive learning models like AudioCLIP and VideoCLIP align diverse modalities—audio, video, image, and text—into shared representation spaces. While memorization in uni-modal and bi-modal models like CLIP has been extensively studied, memorization behavior in multi-modal settings remains largely unexplored.
We introduce MultiMem, the first metric designed to measure memorization across all modalities simultaneously. Our analysis reveals that multi-modal models differ fundamentally from CLIP and single-modality models: cross-modal semantic misalignment, not individual modality quality, is the primary driver of memorization. We show that targeted augmentations can reduce memorization by up to 20% while improving downstream performance by 4–10%.
Why Measure Memorization in Multi-Modal Models?
In supervised learning (SL), models memorize mislabeled or noisy samples. In self-supervised learning (SSL), they memorize atypical patterns. But multi-modal models face a distinct challenge: cross-modal inconsistency.
When captions don’t match images, when audio contradicts video, or when multiple modalities are semantically misaligned, the model must memorize these contradictions to minimize training loss. Existing memorization metrics (like CLIPMem for image-text pairs) fail to capture this global phenomenon across all modalities.
Large-scale multi-modal models are trained on uncurated internet data containing:
- Mislabeled or poorly captioned images
- Audio-visual mismatches (e.g., background noise unrelated to video content)
- Synthetic or AI-generated content with unnatural modality alignment
By measuring and mitigating memorization, we can identify and remove problematic samples, making models both more private and more generalizable.
| Challenge | Traditional Metrics | MultiMem |
|---|---|---|
| Scope | Measure pairwise modality interactions (e.g., image-text) | Measure global consistency across all modalities |
| Limitation | Miss memorization driven by multi-modal interactions | Capture full extent of model alignment |
| Application | Insufficient for accurate assessment | Enables reliable mitigation strategies |
How Does MultiMem Work?
MultiMem extends the leave-one-out framework (used in prior work on SL and SSL) to multi-modal contrastive learning. The metric is computed in three steps:
- Train a model f on the full dataset
- Train a reference model g on the same dataset minus one sample (or a set of samples in practice)
- Measure cross-modal consistency (CMC) for the held-out sample(s) in both models. The difference is the memorization score.
Rather than comparing pairwise similarities (image-text, audio-text, etc.), MultiMem measures global consistency across all modalities, capturing the full extent of how a model aligns diverse inputs.
Computing Cross-Modal Consistency (CMC)
The key innovation in MultiMem is how we measure the quality of multi-modal alignment. For a model with n different modalities, we define the representation matrix Φ for sample xi as:
Φ = [φ̂1, φ̂2, ..., φ̂n]T ∈ ℝn×d
where φ̂j ∈ ℝd is the ℓ2-normalized representation of xi in the j-th modality.
Cross-modal consistency CMC(i, H) is computed as the average similarity across all modality pairs within a sample, minus the average similarity to unrelated samples:
CMC(i, H) = 1⁄2 𝔼[1nT Φ ΦT 1n] − 1⁄2 𝔼[1nT Φi ΦhT 1n]
Interpretation of the formula:
-
First term (positive): Measures the average similarity across all modality pairs within the same sample xi. High values indicate strong alignment between different modalities of the same data point (e.g., audio and video should be aligned if they come from the same source).
-
Second term (negative): Measures the average similarity between modalities of xi and modalities of unrelated samples h from a held-out set H. High values here indicate that the sample is not sufficiently distinguishable from unrelated data.
-
Why subtract? By subtracting the second term, we further amplify the gap between intra-sample alignment and inter-sample similarity, producing a high score when modalities of xi are strongly aligned with each other, but weakly aligned with unrelated examples—which is exactly what the contrastive learning objective aims
-
Averaging over augmentations (the expectation 𝔼): We apply random augmentations during the computation to increase stability and ensure the metric is not tied to a single sampling trajectory.
MultiMem Score
Finally, the MultiMem score for a data point i is the difference in cross-modal consistency between the two models:
MultiMem(i, H, f) = CMCf(i, H) − CMCg(i, H)
where:
- CMC_f: Cross-modal consistency computed using model f trained on the full dataset S
- CMC_g: Cross-modal consistency computed using model g trained on S without sample i
A high MultiMem score indicates that the sample is memorized: removing it significantly changes how well the model aligns all modalities for that sample. A low or negative score indicates the sample is not memorized: the model generalizes to it, so its presence or absence during training doesn’t meaningfully affect the model’s behavior on that sample.
Why This Design Matters
This approach has several advantages over prior metrics:
-
All-modality measurement: Unlike CLIPMem (which only compares image-text pairs), MultiMem captures interactions across all modalities simultaneously.
-
No modality assumptions: The formula works for any number and type of modalities (audio, video, image, text, sensor data, etc.).
-
Robustness: Averaging over augmentations makes the metric stable across different random seeds and initialization patterns.
-
Interpretability: The metric directly measures what contrastive learning optimizes for—alignment within samples, separation between samples.
This approach is robust to dataset splits and held-out set composition, and reveals patterns hidden by partial memorization metrics.
| Property | Details |
|---|---|
| Robustness to held-out set | Performs consistently across random, balanced, and out-of-distribution held-out samples |
| Robustness to dataset splits | Memorization level remains stable across different SC/SI ratio configurations |
| Generality | Applicable to any number and type of modalities |
What Causes Memorization in Multi-Modal Models?
We tested MultiMem on three models across different modal combinations:
| Model | Modalities | Dataset |
|---|---|---|
| AudioCLIP | Audio, Image, Text | UrbanSound8K |
| AVT-CLIP | Audio, Video, Text | MSR-VTT |
| AVIT-CLIP | Audio, Video, Image, Text | MSR-VTT + COCO |
Our analysis revealed three main findings:
Global memorization differs from pairwise memorization. Multi-modal models show higher overall memorization than any single modality pair, indicating that memorization is driven by interactions across all modalities—not by individual modality quality.
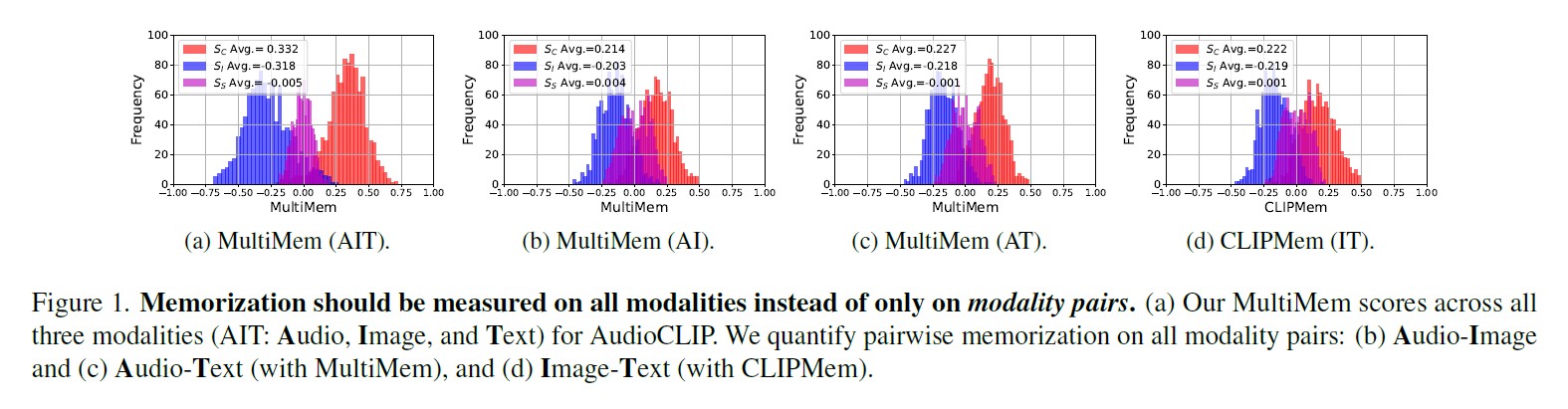
Semantic misalignment is the primary driver. Unlike CLIP (where mislabeled captions cause high memorization), in multi-modal models the most memorized samples have contradictory information across all modalities. Examples include dark videos with text describing motion, or audio unrelated to visual content. The model must memorize these inconsistencies rather than learn generalizable patterns.

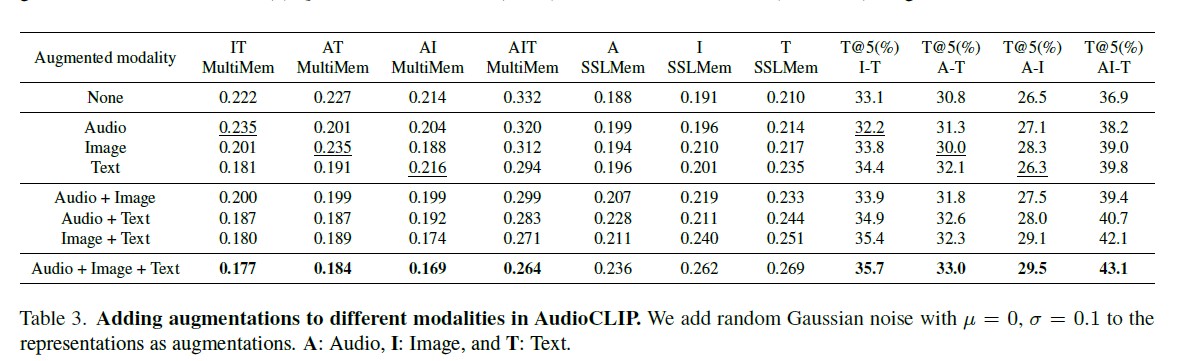
Text dominates but all modalities matter. We ranked modalities by their contribution to memorization: text > video > image > audio. However, removing any single modality still leaves significant memorization, showing that multi-modal models truly require all-modality measurement.
Mitigation Strategies
A new finding for multi-modal contrastive learning: reducing memorization actually improves downstream generalization. This is remarkable because it contradicts traditional learning theory. We propose two strategies to mitigate memorization while preserving utility.
In-Training Mitigation
At every 10-epoch interval, we measure memorization across all training samples using MultiMem. Then, we identify the top 5% most memorized samples and re-group them into new mini-batches. Apply targeted augmentations (Gaussian noise to representations, caption diversity, etc.) only to these samples.
This approach is efficient: the computational overhead is only ~0.70%, with no additional memory requirements.
Post-Training Mitigation
After training, use MultiMem to identify the top N most memorized samples. Remove them and fine-tune on the remaining dataset for additional epochs. Results show that removing 100–200 samples provides the best trade-off, with no need for full retraining—making this more practical for production models.
Results
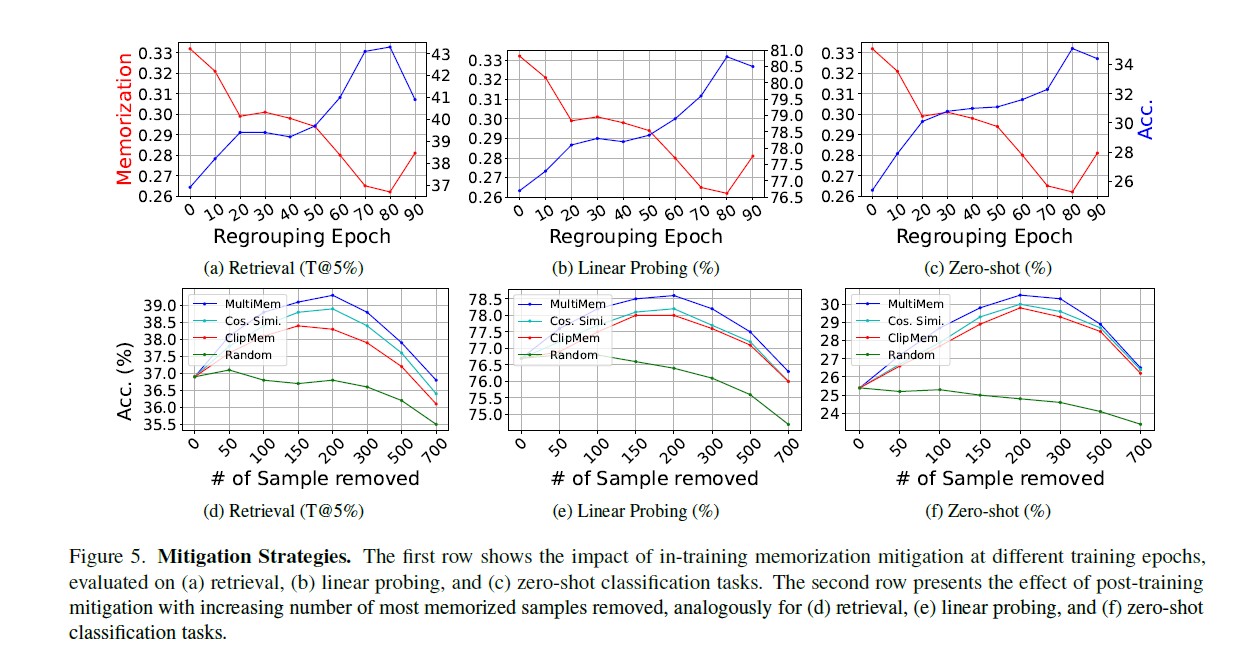
In-Training Mitigation (AudioCLIP)
| Metric | Baseline | In-Training | Improvement |
|---|---|---|---|
| Memorization (↓) | 0.332 | 0.262 | 20.8% reduction |
| Retrieval T@5 (↑) | 36.9% | 43.3% | +6.7% |
| Linear Probing (↑) | 76.7% | 80.8% | +4.1% |
| Zero-Shot (↑) | 25.4% | 35.1% | +9.7% |
Post-Training Mitigation (AudioCLIP)
| Setting | Memorization Reduction | Retrieval Improvement | Zero-Shot Improvement |
|---|---|---|---|
| Removing 150 samples | 12.5% | +2.2% | +4.4% |
| Removing 200 samples | 13.9% | +2.4% | +5.1% |
| Removing 250 samples | 12.9% | +1.9% | +4.9% |
Comparison: In-Training vs Post-Training
In-training mitigation achieves greater memorization reduction and performance gains, while post-training is more practical for already-trained models. Both approaches are more effective than random removal or gradient-based methods.
Why This Matters
Large-scale multi-modal models are trained on uncurated data scraped from the internet. These datasets inevitably contain:
- Mislabeled or poorly captioned images
- Audio-visual mismatches (e.g., background noise unrelated to video content)
- Synthetic or AI-generated content with unnatural modality alignment
By using MultiMem, practitioners can:
- Identify highly memorized samples in the model and help models de-memorize them,
- Identify problematic training data without manual inspection. Remove samples that hurt model generalization,
- Build more robust, privacy-preserving, and generalizable models.
What Are the Main Takeaways?
- Memorization in multi-modal models is driven by cross-modal semantic misalignment, not individual modality quality.
- Global memorization measurement is necessary—pairwise metrics miss critical interactions.
- Text dominates modality contributions, but all modalities matter for accurate assessment.
- Reducing memorization improves generalization in multi-modal contrastive learning, unlike traditional supervised learning.
- Both in-training and post-training mitigation are effective, with trade-offs in computational cost and performance gain.
- Targeted augmentations can reduce memorization by up to 20% while improving downstream tasks by 4–10%.
BibTeX
@inproceedings{wang2026multimem,
title = {MultiMem: Measuring and Mitigating Memorization in Multi-Modal Contrastive Learning},
author = {Wang, Wenhao and Boenisch, Franziska and Backes, Michael and Dziedzic, Adam},
booktitle = {Proceedings of the European Conference on Computer Vision},
year = {2026},
note = {Accepted at ECCV 2026},
url = {https://arxiv.org/abs/2606.22220}
}