![]()
Accepted at ICML 2026
Finding DoRI  : Discovery of
: Discovery of
Retained Images in
Diffusion Models
Antoni Kowalczuk1,*,
Dominik Hintersdorf2,3,*,
Lukas Struppek6,*,†
Kristian Kersting2,3,4,5,
Adam Dziedzic1,
Franziska Boenisch1
1 CISPA Helmholtz Center for Information Security
2 German Research Center for Artificial Intelligence (DFKI)
3 Technical University of Darmstadt
4 Hessian Center for AI (Hessian.AI)
5 Centre for Cognitive Science, Technical University of Darmstadt
6 Far.AI
* Equal contribution. † Work mainly done at DFKI/Technical University of Darmstadt.
Paper | Code | Poster | Slides | Recording | BibTeX
On This Page
Overview · Main Finding · Problem · Key Idea · Our Method · Locality Evidence · Results · Mitigation Tradeoffs · Take-Aways · Citation
Overview
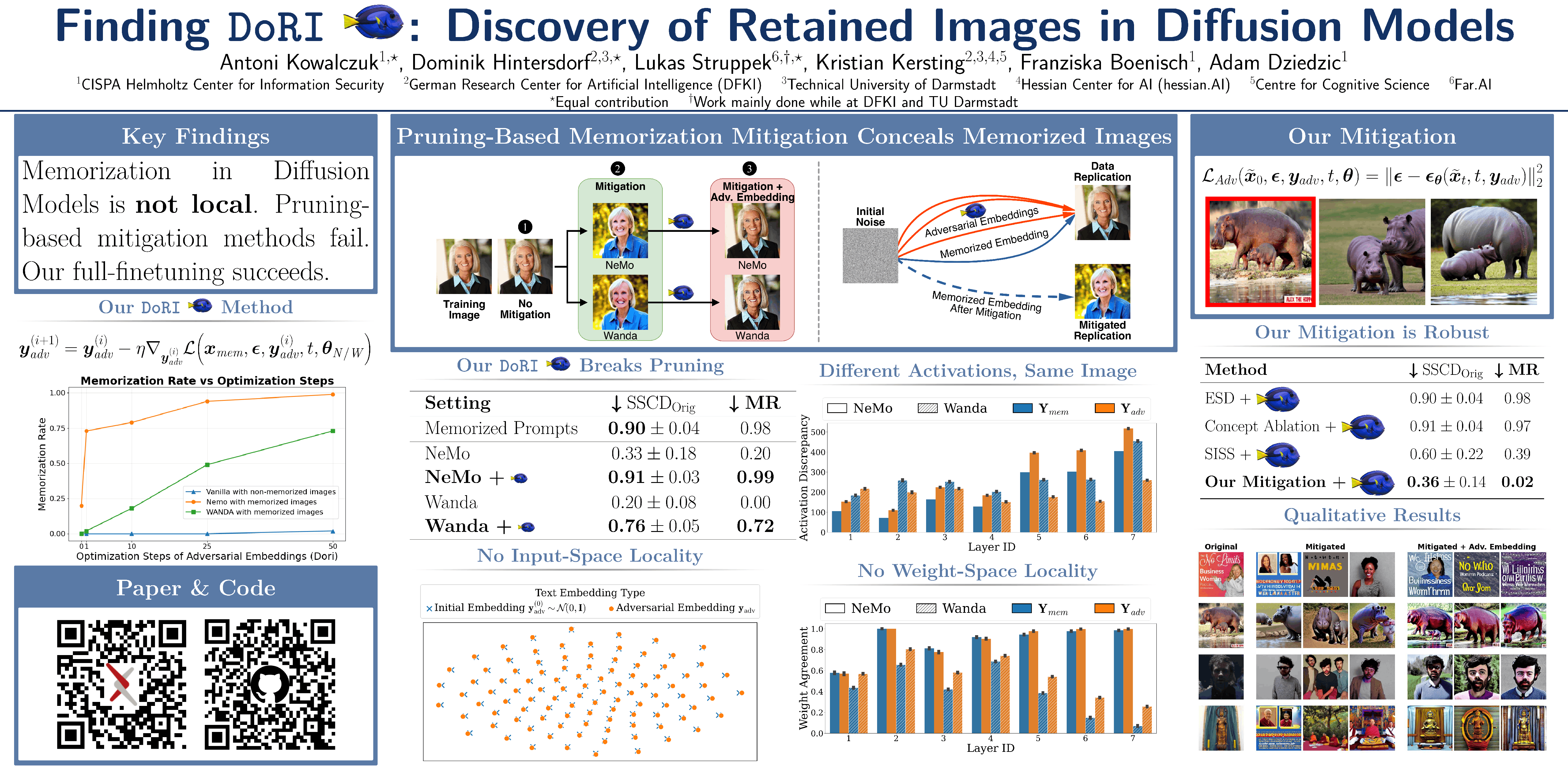
We study whether memorized training images in text-to-image diffusion models are actually removed by pruning-based mitigation methods. The central finding is that these methods can suppress replication for the original prompt while leaving alternative text embeddings that still recover the same image.
DoRI searches directly in continuous text-embedding space for such adversarial triggers. The experiments suggest that memorization is not localized in a small set of weights or limited to one prompt or one activation pattern, and that robust mitigation should be evaluated against diverse replication triggers.
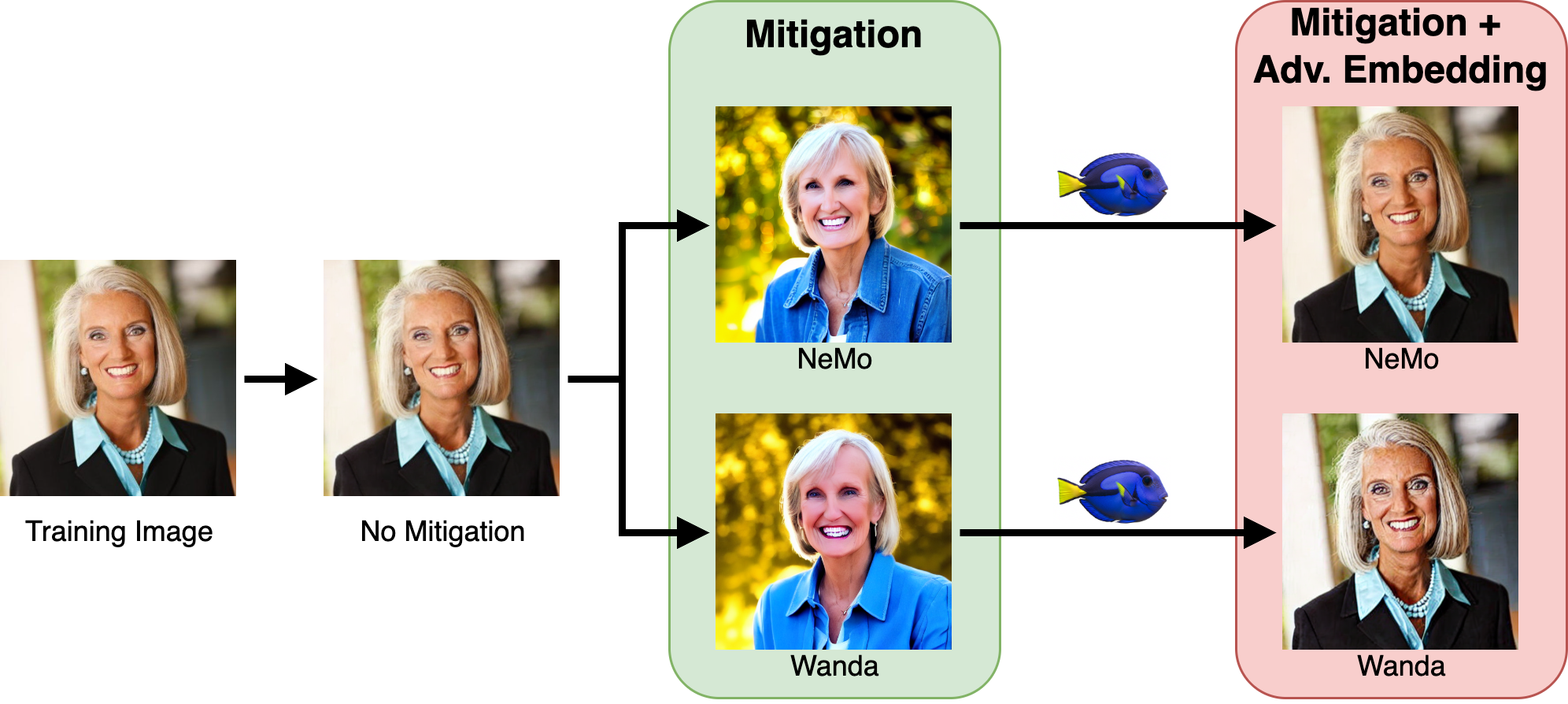
The central failure mode: pruning changes the generation for the original prompt, but DoRI finds adversarial embeddings that retrieve the retained image again.
Main Finding
Text-to-image diffusion models (DMs) have achieved remarkable success in image generation. However, concerns about data privacy and intellectual property remain due to their ability to inadvertently memorize and replicate training data. Recent mitigation efforts have focused on identifying and pruning weights responsible for triggering verbatim training data replication, based on the assumption that memorization can be localized. We challenge this assumption and demonstrate that, even after such pruning, small perturbations to the text embeddings of previously mitigated prompts can re-trigger data replication, revealing the fragility of such methods.
Our analysis provides multiple indications that memorization is not inherently local in diffusion models: (1) replication triggers for memorized images are distributed throughout text embedding space; (2) embeddings yielding the same replicated image produce divergent model activations; and (3) different pruning methods identify inconsistent sets of memorization-related weights for the same image. Finally, we show that bypassing the locality assumption enables more robust mitigation through adversarial fine-tuning. These findings provide new insights into the fundamental nature of memorization in text-to-image DMs and inform the future development of more reliable mitigation methods against DM memorization.
Problem: Pruning can hide replication without removing memorization
Verbatim data replication in text-to-image diffusion models creates privacy and intellectual-property risks, especially for open-weight models. Existing mitigation methods such as NeMo and WANDA identify weights associated with memorized prompts and prune them. This can stop the original caption from reproducing the training image, which makes the mitigation appear successful under standard prompt-based evaluation.
The paper asks whether that apparent success means the memorized image has been removed from the model. This distinction matters: deployment filters or single-prompt pruning can reduce one access path, but model release requires confidence that the retained image cannot be recovered through nearby or alternative inputs.
Key Idea: Search beyond natural-language prompts
DoRI treats the text conditioning vector itself as the search variable. Starting from the memorized prompt embedding, it optimizes an adversarial embedding with the diffusion training loss for a known memorized image. Noise and denoising timesteps are resampled during the optimization so that the final embedding is not tied to a single sampling trajectory.
If a pruned model still generates the target training image from this optimized embedding, then the pruning did not erase the memorized content. It only disrupted the original retrieval path.
After WANDA mitigation, standard generations move away from the original image, while adversarial embeddings can steer generation back toward close replicas.

Our Method: Adversarial embeddings expose retained images
The method assumes a model developer has already identified a memorized image and its prompt. After applying NeMo or WANDA, DoRI optimizes a continuous text embedding against the target image under the pruned model. The optimized embedding is then used as the conditioning input for generation.
The analysis goes beyond showing that we can re-generate memorized images after the pruning methods. We also probe whether memorization is local in text-embedding space, internal activations, and selected weights. Across these views, the evidence points away from a local mechanism of memorization in diffusion models and toward a distributed retention pattern.
Locality Evidence: Retained images are not tied to one local trigger
We test locality from three angles.
In embedding space, optimized triggers for a single memorized image remain widely distributed. Randomly initialized or non-memorized prompt embeddings can be optimized into successful triggers, so retrieval is not confined to the original caption neighborhood. In general, adversarial triggers are widely scattered in text-embedding space.
For activations, triggers for the same retained image do not converge to one consistent activation pattern, weakening activation-localization assumptions. Successful triggers for the same image can produce divergent activations.
Finally, different pruning procedures identify inconsistent memorization weights for the same image, which makes small-subset removal brittle. Low agreement between selected weights undermines local pruning.
| View | What we check | Main implication |
|---|---|---|
| Embedding space | Randomly initialized or non-memorized prompt embeddings can be optimized into successful triggers. | Retrieval is not confined to the original caption neighborhood. |
| Activations | Triggers for the same retained image do not converge to one consistent activation pattern. | Activation-localization assumptions are weak. |
| Weights | Different pruning procedures identify inconsistent memorization weights for the same image. | Small-subset removal is brittle. |
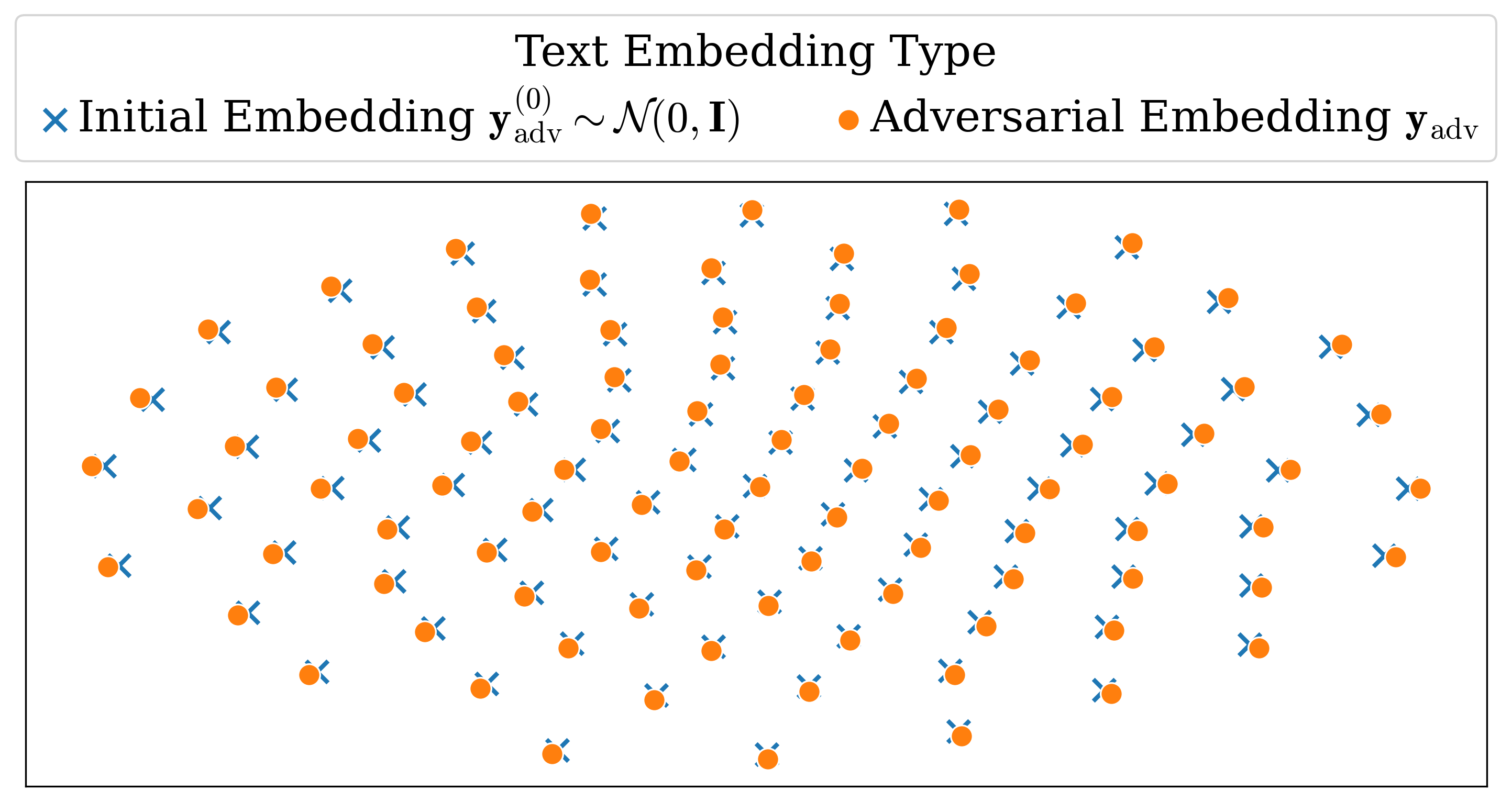
Adversarial triggers are widely scattered in text-embedding space.
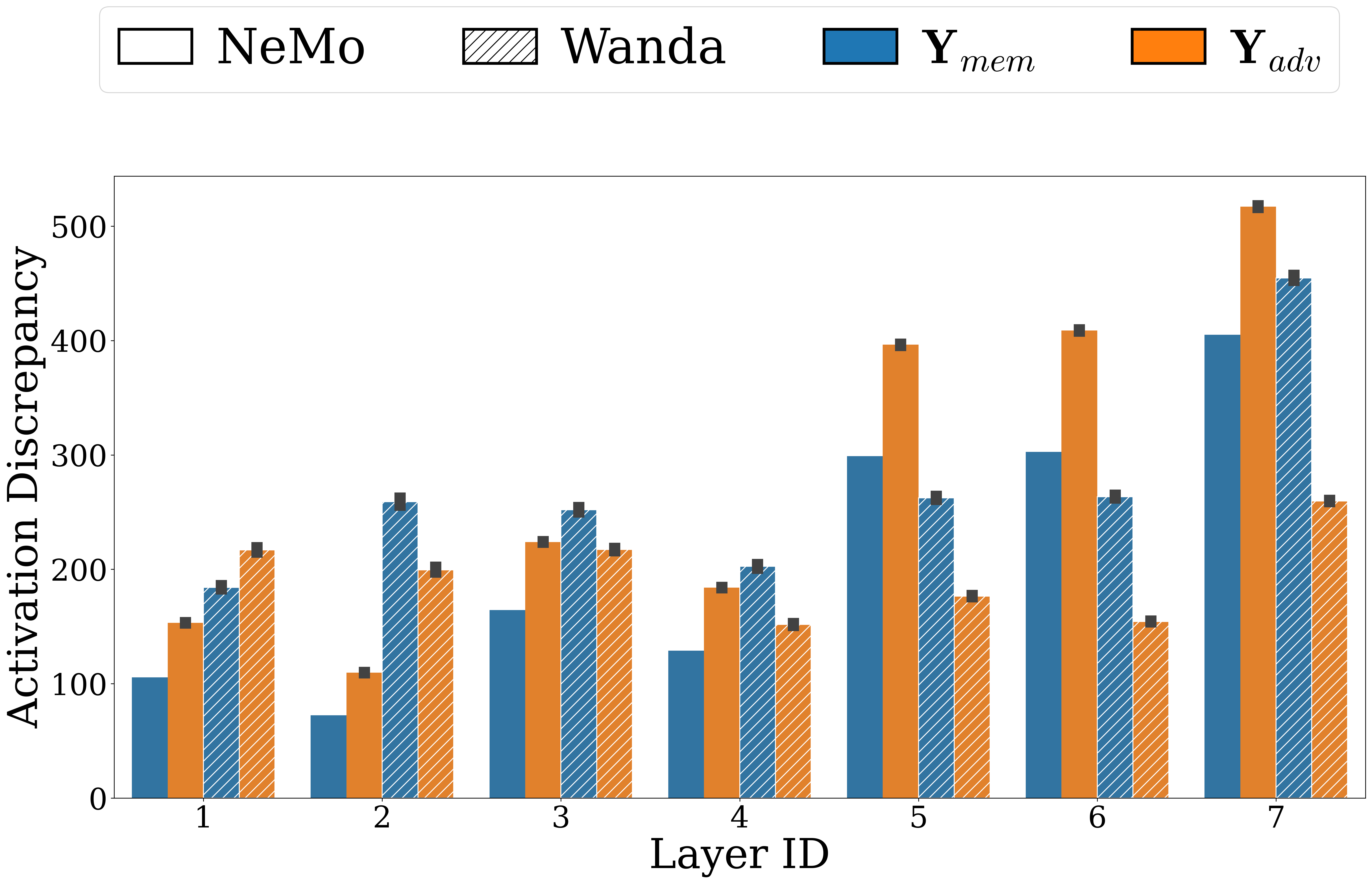
Successful triggers for the same image can produce divergent activations.
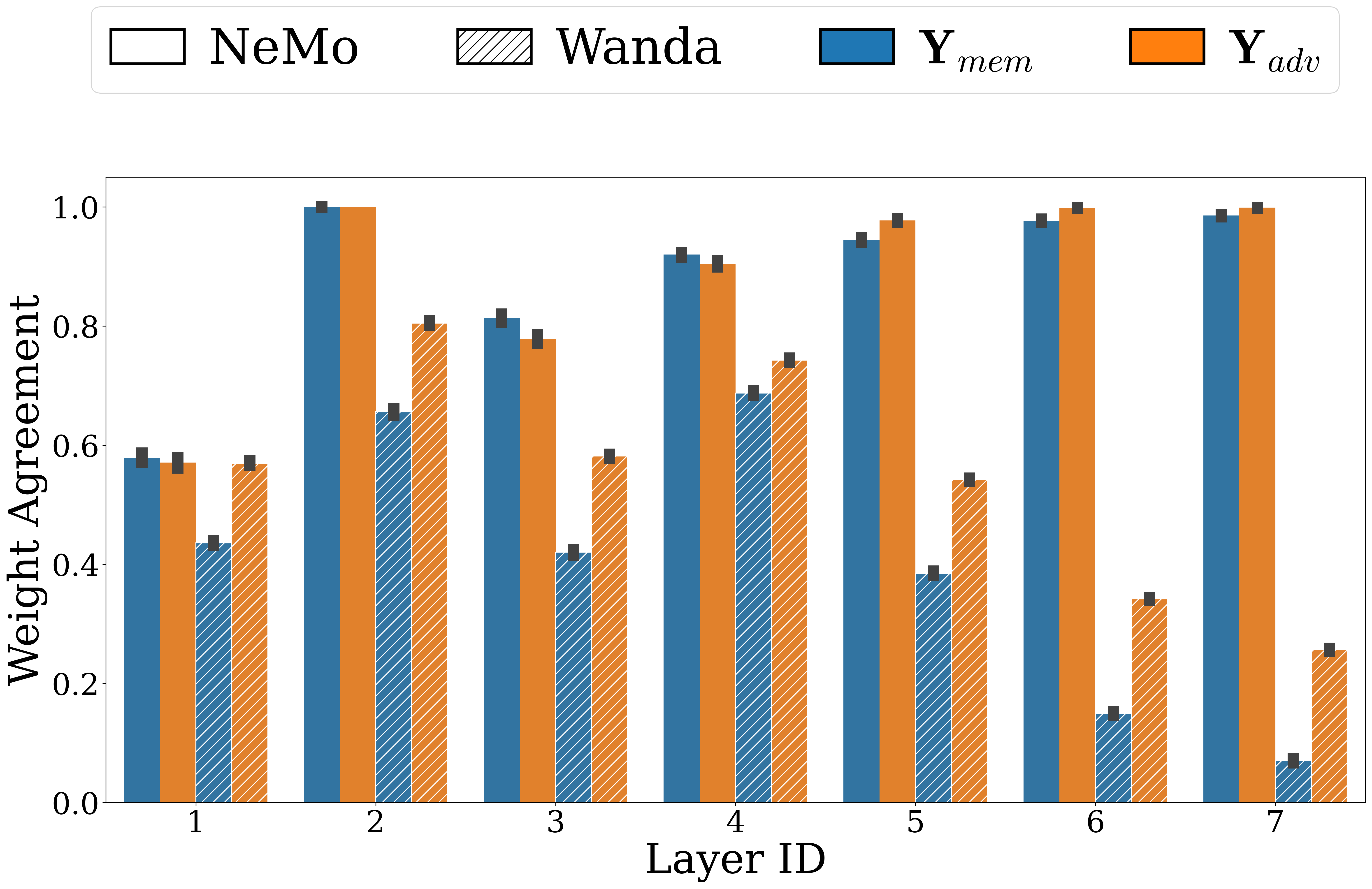
Low agreement between selected weights undermines local pruning.
Key empirical findings
We show that NeMo and WANDA reduce replication under the original memorized prompts, but adversarial embeddings recover a high Memorization Rate (MR) after pruning. In the main table below, NeMo with DoRI reaches MR 0.99 and WANDA with DoRI reaches MR 0.72 for verbatim memorized samples. Additionally, we report SSCDOrig, which is a mean cosine similarity of feature embeddings from the SSCD model between the original image and the image generated by the model. Values above 0.7 indicate replication.
For Stable Diffusion v2.0, the same pattern appears: pruning lowers standard prompt replication, while DoRI adversarial embeddings recover high similarity to the memorized target.
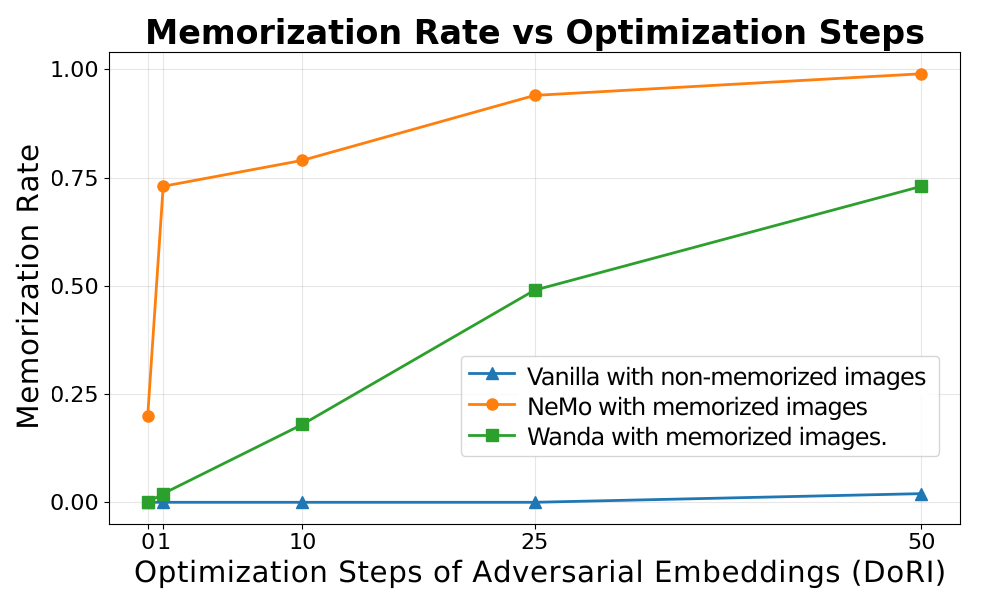
Memorization rate rises quickly for adversarial embeddings targeting memorized images, while the non-memorized baseline remains near zero.
| Setting | ↓ SSCDOrig | ↓ MR |
|---|---|---|
| Memorized prompts | 0.90 ± 0.04 | 0.98 |
| Non-memorized prompts | 0.17 ± 0.05 | 0.00 |
| Non-memorized prompts + DoRI | 0.48 ± 0.06 | 0.00 |
| NeMo | 0.33 ± 0.18 | 0.20 |
| NeMo + DoRI | 0.91 ± 0.03 | 0.99 |
| WANDA | 0.20 ± 0.08 | 0.00 |
| WANDA + DoRI | 0.76 ± 0.05 | 0.72 |
DoRI optimization does not reproduce non-memorized examples in the same way, but it can recover memorized examples after NeMo or WANDA pruning as optimization steps increase.
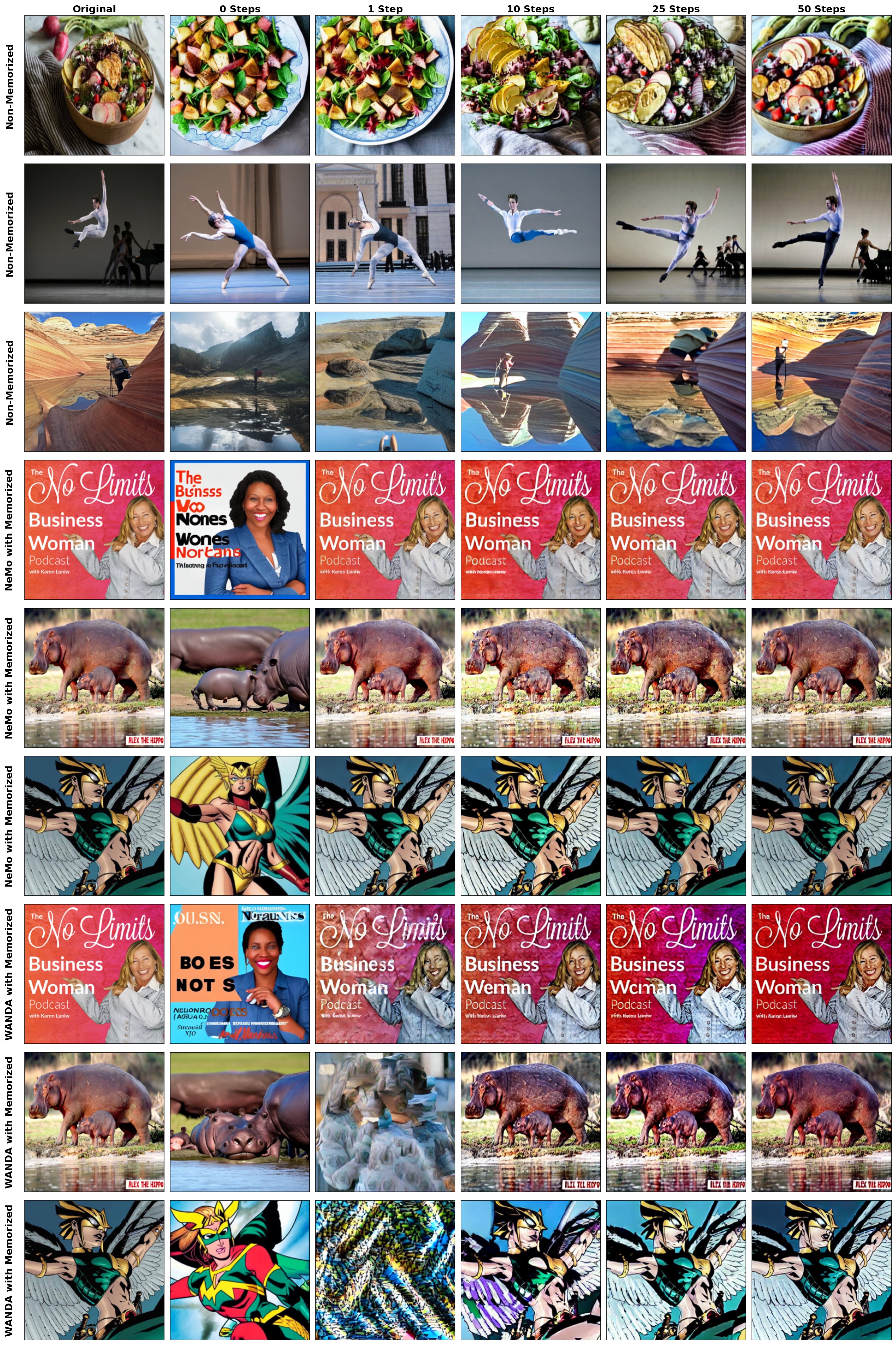
Mitigation Tradeoffs: Robust removal needs more than pruning
Simply increasing WANDA sparsity can make DoRI fail, but this is due to large concept-quality degradation on related prompts. In contrast, adversarial fine-tuning updates the full model with diverse adversarial embeddings and surrogate images, reducing replication while preserving general image generation quality more effectively.
After adversarial fine-tuning, adversarial embeddings no longer recover close replicas in the same way as after pruning.
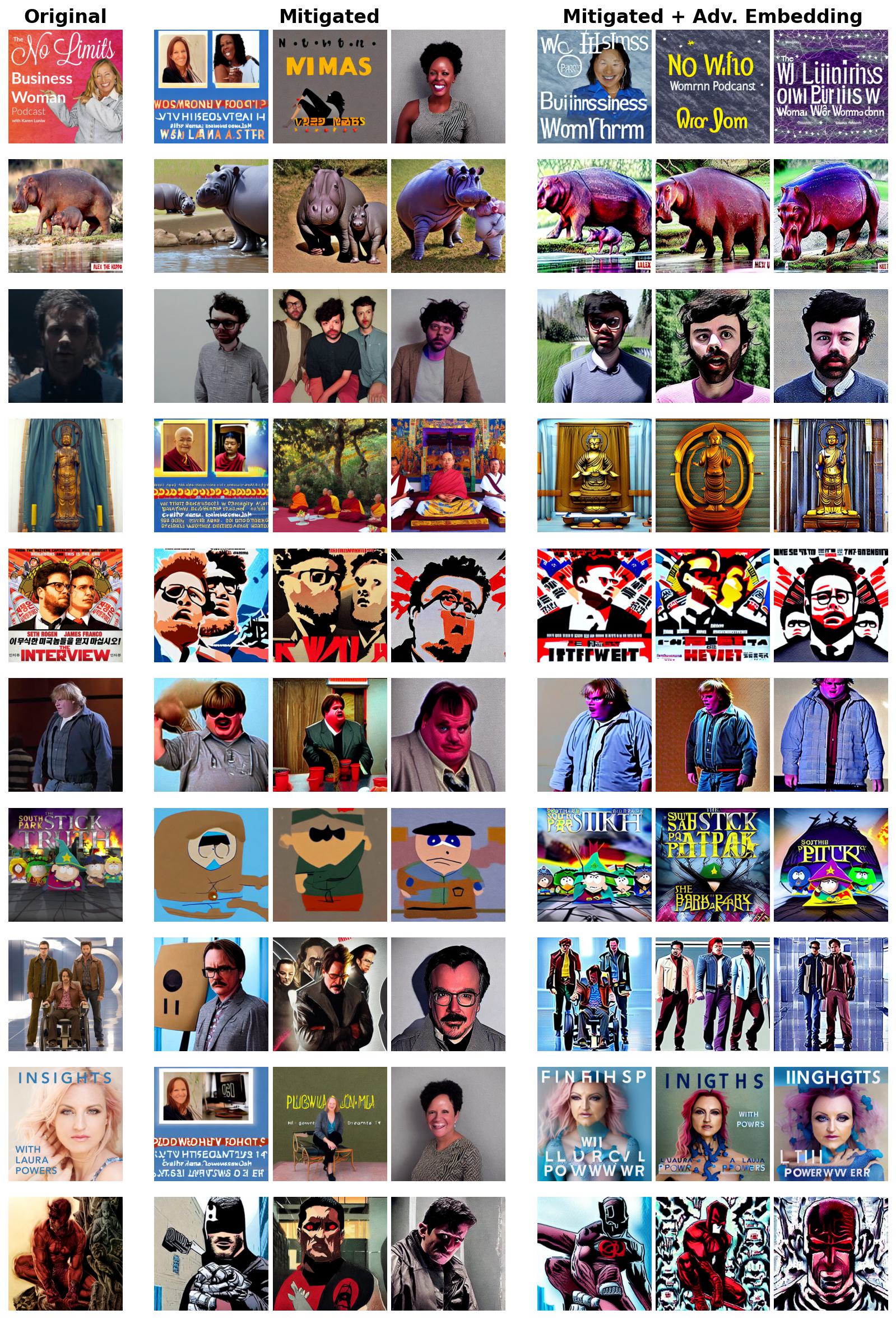
WANDA at 10 percent sparsity can suppress retrieval, but the paper shows visible damage on semantically related concept prompts.

{kind=link}
| Setting | ↓ SSCDOrig | ↓ MR | Additional signal |
|---|---|---|---|
| ESD + DoRI | 0.90 ± 0.04 | 0.98 | Concept-removal transfer still fails under DoRI. |
| Concept Ablation + DoRI | 0.91 ± 0.04 | 0.97 | Also remains vulnerable to adversarial embeddings. |
| Our mitigation + DoRI | 0.36 ± 0.14 | 0.02 | Five-epoch adversarial fine-tuning result in the main paper. |
| SD v2: NeMo + DoRI | 0.87 ± 0.02 | 1.00 | Failure mode generalizes beyond Stable Diffusion v1.4. |
| SD v2: Our mitigation + DoRI | 0.14 ± 0.06 | 0.06 | Adversarial fine-tuning remains effective on SD v2. |
| WANDA 10% + DoRI | 0.40 ± 0.13 | 0.01 | AConcept drops to 0.33; FIDConcept is 80.70. |
What Are the Main Take-Aways?
- Single-prompt evaluation can overstate whether memorization has been removed.
- Replication triggers can exist outside the original natural-language prompt.
- Different successful triggers can produce divergent activations for the same retained image.
- Pruning-based localization does not identify a set of memorization weights.
- Mitigation should be tested against diverse adversarial retrieval paths, not only the original caption.
BibTeX
@inproceedings{kowalczuk2026findingdori,
title = {Finding DoRI: Discovery of Retained Images in Diffusion Models},
author = {Kowalczuk, Antoni and Hintersdorf, Dominik and Struppek, Lukas and Kersting, Kristian and Dziedzic, Adam and Boenisch, Franziska},
booktitle = {Proceedings of the International Conference on Machine Learning},
year = {2026},
note = {Accepted at ICML 2026},
url = {https://arxiv.org/abs/2507.16880}
}
Finding DoRI: Discovery of Retained Images in Diffusion Models. ICML 2026.
Paper
|
Code
|
Poster
|
Slides
|
Recording