Private Adaptations of Open LLMs Outperform their Closed Alternatives
by Adam Dziedzic and Franziska Boenisch
Nowadays, Large Language Models (LLMs) perform a plethora of language tasks. OpenAI exposes its GPT4 model to perform tasks, such as text generation, translation, dialog summarization, code generation, and many others. While closed LLMs, like GPT4, are exposed via public APIs or web interfaces, for open LLMs, like Llama, their parameters (i.e., their weights) are directly released and allow us to simply download them and and run the model locally. Therefore, we sometimes call these models “open-weight LLMs”. Both types of models, open and closed ones, even though they have strong zero-shot performance, they still require adaptations, such as prompting or fine-tuning to perform well on specialized downstream tasks. Given that downstream tasks often rely on sensitive data, we need to ensure this data’s privacy when adapting LLMs.
In this blog post which is based on our latest NeurIPS 2024 paper, we compare private adaptations for open vs. closed LLMs on multiple axes and find that by adapting open LLMs instead of closed ones, we can preserve more privacy and obtain higher performance at lower cost. On the way, we also design novel private prompting methods for generative tasks. Let’s explore how we do that.
Open LLMs have comparable performance to Closed LLMs
The most recent results from standard benchmarks (such as MMLU that measures knowledge acquired by LLMs during pretraining) show that open-weight LLMs such as Llama 3.1 405 B closed the gap in performance with closed-source LLMs for the first time. This is a great starting point for our research.
How to Adapt your LLM
As we mentioned above, LLMs perform well on general understanding tasks, however, they do not perform well enough on specialized downstream tasks. For example, for the DBpedia task, that aims to classify Wikipedia articles, we observe that after adapting the LLM to the task, we can boost the performance by more than 40%. This motivates the why it is important to adapt the models. Additionally, behind the scenes, the training of entire large LLMs from scratch is a costly venture. Hence, adaptations are a computationally reasonable alternative. Let’s dive into how we can adapt LLMs:
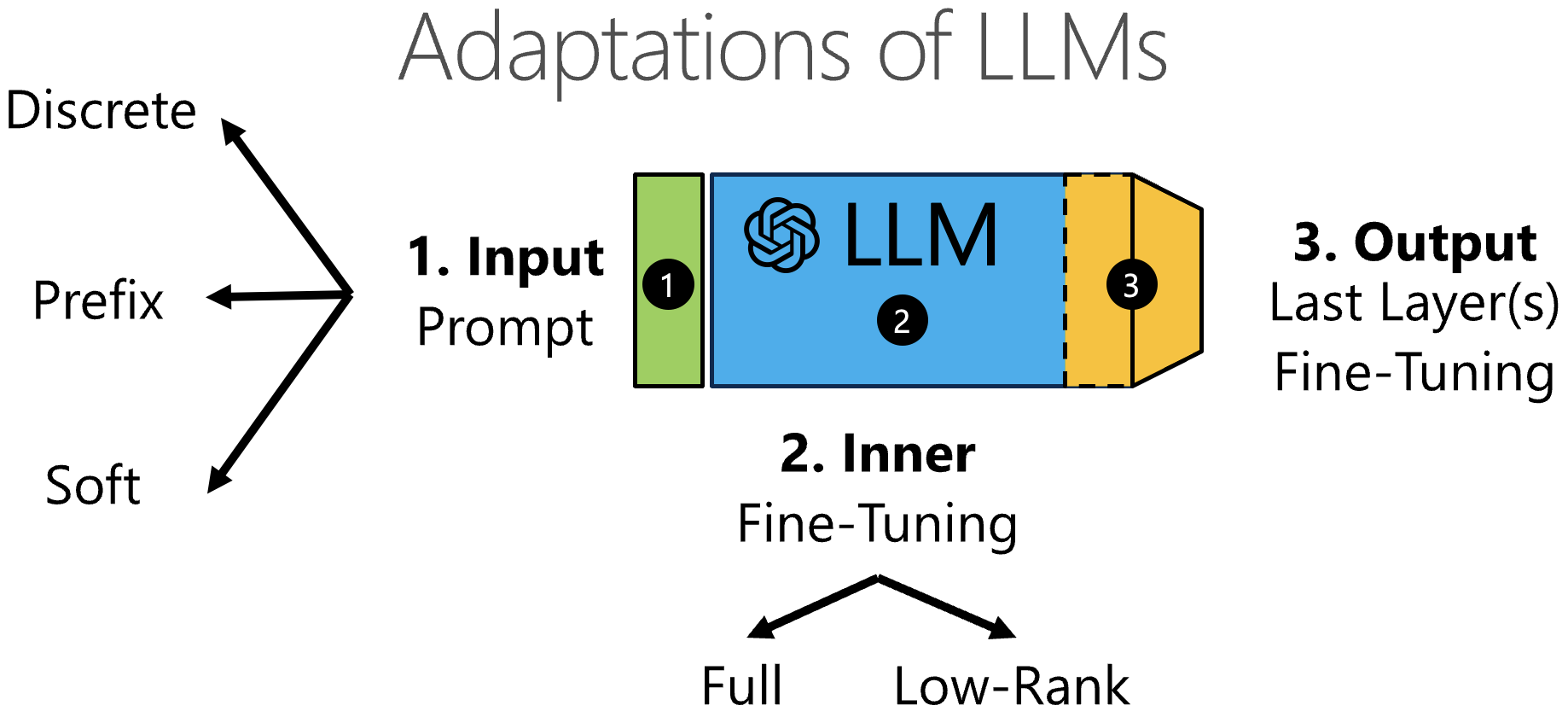
Figure 1: The different ways of adapting LLMs.
One of the most popular ways to adapt LLMs is through prompting (denoted as 1. Input Prompt in Figure 1). The input prompts can be discrete where you prepend additional natural language text to your standard input. On the other hand, soft prompts are a learnable set of parameters prepended to the input embeddings. Prefix tuning is similar to the soft prompt but apart from being prepended to the input, it can also be prepended to every attention layer.
The second approach to adapt LLMs is through inner fine-tuning (the 2nd adaptation in Figure 1). You can do it either through full fine-tuning, where you adjust all the parameters of your LLM, or using a low-rank adaptation, abbreviated as LoRA, where a small set of additional parameters are added to many layers inside an LLM. Finally, we can fine-tune a couple of the last layers or even add an additional layer or more layers on top of an LLM (the 3-rd type of adaptation in Figure 1).
Important!!! If you want to adapt a closed LLM such as GPT4, due to the API restrictions, you can only use discrete prompts or last-layer fine-tuning. These adaptations are less performant than gradient-based adaptations that we can use on open LLMs.
More privacy is leaked through adaptations of closed vs open LLMs
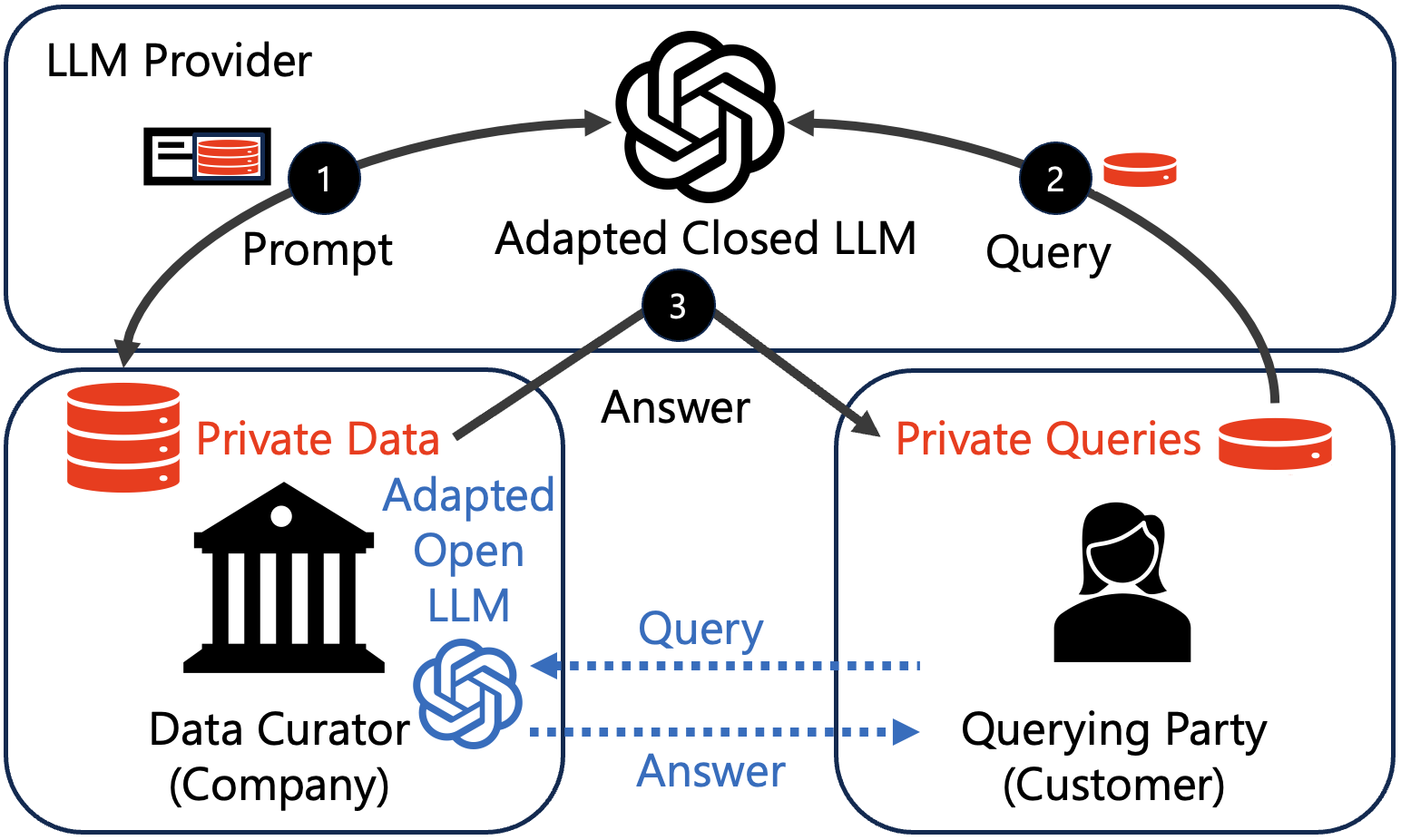
Figure 2: How privacy can leak from closed LLMs.
When we want to reason about privacy leakage from LLM adaptations, it helps to understand the stakeholders that are involved in practice. We identified the data curator, e.g., a company that holds their customers’ private data. The company wants to adapt an LLM on this private data to solve a task for (potentially new) customers, i.e., querying parties. In case of a closed LLM, there is also an LLM provider, i.e., a company like OpenAI that deploys the models, such as GPT4.
With these stakeholders defined, let’s now look into the difference in privacy leakage between open and closed LLMs.
Open LLMs. The data curator can locally adapt an open LLM on their private data so that it can cater to a specific downstream task. Then, a customer can query the adapted open LLM. In this case, the customer sends the query directly to the party hosting the LLM and no third parties are involved in the process. The only privacy concern arises since the querying party might be malicious. In this case, the private information from the data curator can leak to the querying party through the returned answers of the prompted LLM.
Closed LLMs. Let us also consider the case when the data curator does not have any open LLM on-premise and would like to use a closed LLM from a model provider, for example, GPT4 exposed by the API from OpenAI. First, the closed LLM must be adapted to the private data. For the closed LLMs, this can be done by discrete prompts. This setup induces multiple axes of possible privacy leakage: For adaptation, the private data has to be directly released to the LLM provider (case 1 in Figure 2). Additionally, the private queries from a customer must be routed through the LLM provider. Thus, also the private queries from the customers leak to the LLM providers (case 2). Finally, in the same way as with open LLMs, the answers can leak information contained in the private data to the querying party (case 3).
Overall, this conceptual analysis shows that the privacy leakage is much higher when adapting closed LLMs vs open LLMs. While for open LLMs, only answers can leak some private information, with closed LLMs, the private data and queries leak to the provider of the closed LLM.
Next, we will investigate how to prevent privacy leakage.
Private LLM Adaptations for text generation
To obtain private LLM adaptations, we build on the mathematical framework of Differential Privacy (DP). For LLM adaptations, DP formalizes the intuition that adaptations learned on two neighboring datasets, i.e., datasets that differ in only one data point, will induce roughly the same behavior of the adapted LLM. The roughly is expressed in a privacy budget parameter ε.
Within all existing DP prompting methods, we identified that there is a lack of support for text generation tasks (e.g., dialog summarization). Instead, most prior work on private prompting focuses on classification tasks. This is a big gap since LLMs are generative models that solve inherently much more complex tasks than classification.
To understand our methods on private prompts for generative tasks, it might be helpful if you first check out our other blog post here, where we introduced the first private prompts for LLMs. Here, we only give you a short intuition on how our generation methods work. If you are interested in the details, feel free to check out our paper.
To enable private text generation with discrete prompts, we build on the differentially private PATE algorithm and introduce a privacy-preserving knowledge transfer from an ensemble of teacher prompts to a student prompt. The resulting method is called PromptDPSGDGen. For methods like soft prompts or prefix, we adjust the differential private stochastic gradient descent (DPSGD) algorithm. This method for text generation, called PromptDPSGDGen obtains the input gradients from the LLM and performs DPSGD to update the soft prompt parameters while keeping the underlying LLM frozen.
Private LLM Adaptations on open LLMs outperform their closed alternatives
We carried out an in-depth comparison of the adaptations of open vs closed LLMs considering 1) privacy protection, 2) performance, and 3) cost. The privacy protection is assessed in terms of the leakage of private data either to the LLM provider or the querying party (a user of the adapted LLM), as well as the leakage of the users’ queries to the LLM provider. The performance is measured in terms of accuracy for classification tasks and scores like Rouge or BLEU for text generation tasks at a given privacy budget ε. Finally, the cost is the amount of money in dollars needed to adapt a given LLM with privacy.
We analyzed four recent methods to adapt closed LLMs, including our PromptPATEGen. All of them were designed for closed LLMs to prevent the leakage of private data to the querying party. All of them fulfill this goal. However, they leak private data and queries to the LLM provider. The only method that does not leak private data to the LLM provider is DP-OPT. But DP-OPT requires the data curator to use an additional open LLM on-premise. For open LLMs, we compare private fine-tuning, soft prompts, including our PromptDPSGDGen, and private LoRA. When applied to an open local model, none of them leaks private data and queries to an external LLM provider.
Overall, we find that the adaptations of open LLMs offer higher privacy protection and higher performance at lower cost. On the other hand, the prompt-based adaptations for closed LLMs provide lower privacy protection and lower performance at a higher cost compared to their open counterparts. We further analyze the privacy-utility trade-off for classification and generation tasks across different privacy budgets. Let’s look into some numbers: For Table 1 below, we adapted open and closed LLMs on dialog summarization (SAMSum dataset). The metrics used to report performance are Rouge scores. Rouge-1 assesses how many unigrams in the generated text agree with the expected LLM output. Rouge-2 is similar but uses bi-grams. Rouge-L refers to the similarity of the longest common subsequence between prediction and target. In terms of cost, for closed LLMs, we aggregate the costs incurred by the API over adaptation and querying. For open LLMs, we estimate the costs through costs that would be incurred by adapting and querying the LLM on cloud hardware. The cost is, hence, dependent on the time it takes to adapt and query on the cloud hardware. In both cases, open and closed model adaptations, for comparability, we assume 10k queries.
In the following table, we present some insights on adaptation for closed LLMs (DP-ICL and PromptPATEGen) and open LLMs (PromptDPSGDGen and Private LoRA). For more results on all methods and various LLMs, check our paper.
| Adaptation | LLM | Rouge-1 | Rouge-2 | Rouge-L | Cost ($) |
|---|---|---|---|---|---|
| DP-ICL | GPT4-Turbo | 41.8 | 17.3 | 33.4 | 3419 |
| PromptPATEGen | Open Llama 13B | 43.4 | 19.7 | 34.2 | 19.43 |
| PromptDPSGDGen | BART Large | 46.1 | 21.3 | 37.4 | 2.13 |
| Private LoRA | BART Large | 48.8 | 23.5 | 39.1 | 3.59 |
| Private LoRA | Mixtral 8x7B | 52.8 | 29.6 | 44.7 | 67.95 |
Table 1: Comparison of private open vs closed LLM adaptations on SAMSum at a privacy budget of ε=8.
What is striking is that the adaptations for open LLMs achieve higher performance, expressed by higher Rouge scores, on significantly smaller models (BART with 355M parameters vs the significantly larger GPT4-Turbo and Open Llama with 13B parameters). This performance is achieved at a fraction of costs. If we are willing to spend slightly more money and deploy a larger open LLM, such as Mixtral, the performance gain from the adaptation of the open LLM is even more significant than for the closed adaptations.
Conclusions
Let’s summarize the results. Open LLMs are:
- more private than closed LLM adaptations since they have significantly fewer possibilities for privacy leakage;
- more performant than closed LLM adaptations: at the same privacy level, even using much smaller models, we can obtain higher performance with open LLMs due to their ability to support gradient-based adaptation methods;
- more cost-effective than closed LLM adaptations that incur continuous query costs to an LLM provider.
If you’d like to learn more, read our NeurIPS 2024 paper “Open LLMs are Necessary for Current Private Adaptations and Outperform their Closed Alternatives”. It goes into greater detail about our research on this topic.