BitMark: Watermarking Bitwise Autoregressive Image Generative Models
CISPA Helmholtz Center for Information Security
Autoregressive image models like Infinity and Instella IAR are now competitive with diffusion models for high‑quality text-to-image generation. But as generated images get reused as training data, we risk model collapse: models increasingly train on their own outputs, amplifying artifacts and drifting from natural data.
BitMark is the first watermarking framework tailored to bitwise autoregressive image models. It embeds a watermark at generation time that is:
- Hard to remove without degrading image quality.
- Efficient to generate and detect.
- Radioactive – its signal persists even when other models are trained on watermarked images.
This radioactivity lets model owners track provenance across training cycles and avoid training future models on their own outputs.
Background: Bitwise Autoregressive Image Models
VAR and its extension Infinity generate images autoregressively, scale-by-scale:
- Images are quantized into discrete codes and predicted as sequences.
- Infinity uses bitwise prediction with a large implicit codebook and binary spherical quantization.
- Random bit flipping during generation allows self-correction across scales.
Instella IAR also adopts a bitwise next‑patch prediction scheme, using very few tokens (e.g., 128) for a 1024×1024 image.
These models work at the bit level internally, which is where BitMark is applied.
Why Bit-Level Watermarking?
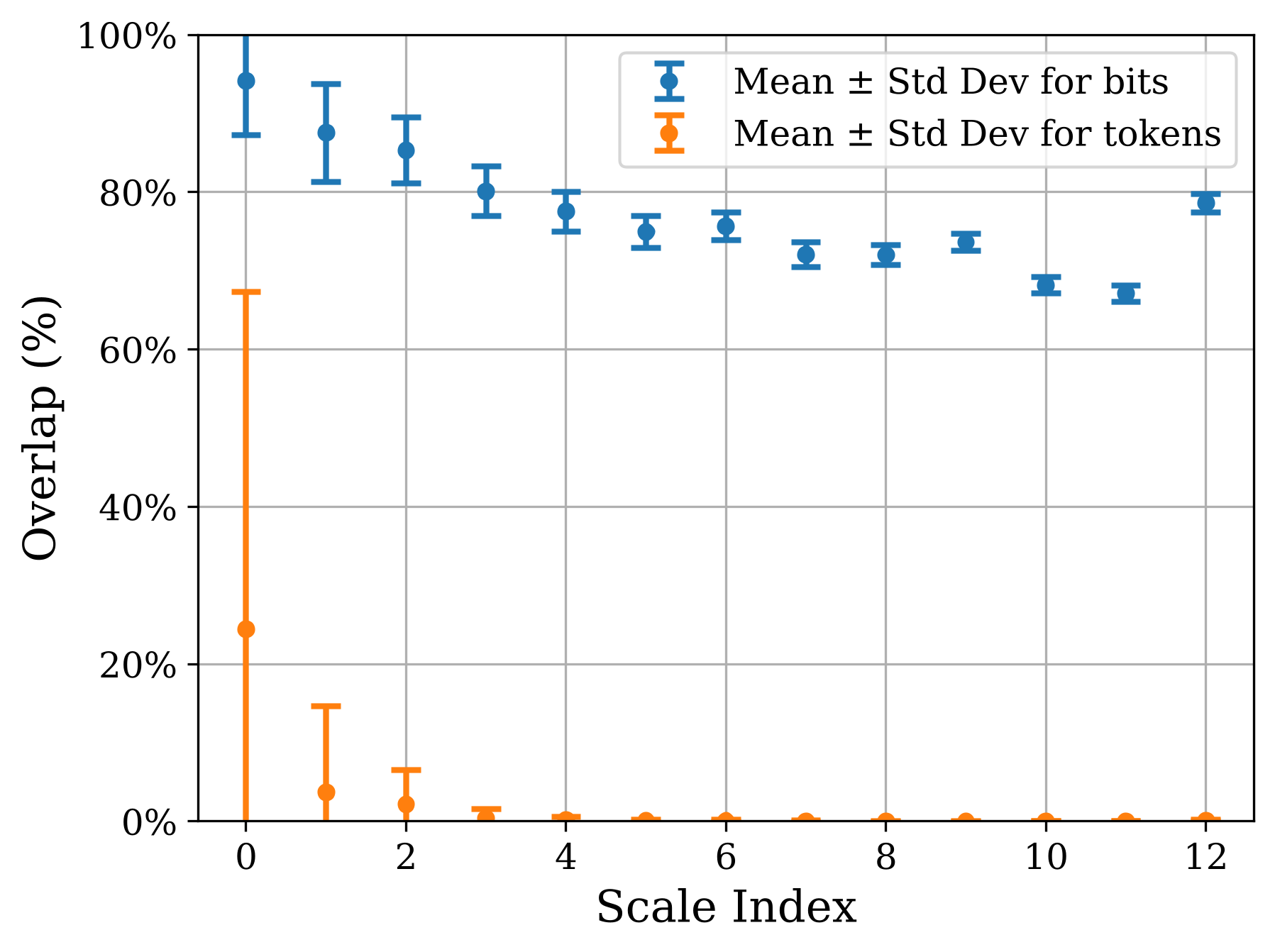
Unlike LLMs, where decoding and re-encoding text reconstructs the exact same tokens, Infinity’s:
- Token overlap after decode–re-encode is very low (~2.4%).
- Bit overlap is much higher (~77%).
So bits are far more stable than tokens, given the large codebook. This motivates embedding and detecting watermarks in bit space, not at the token or pixel level.
The BitMark Watermark
Embedding: Biasing Green Bit Sequences
BitMark follows the “green/red list” idea from LLM watermarking:
- Consider all bit sequences of length
n:S = {0,1}^n. - Assign them to a green list
Gand a red listR - During autoregressive generation, whenever a bit would complete a sequence in
G, BitMark adds a small biasδto the corresponding logit before sampling.- Because only these high-entropy bits are slightly nudged and therefore influenced, image quality and semantics are essentially preserved.
Result: Watermarked images have a higher fraction of green sequences than natural or non-watermarked images.

As can be seen in this example of a dog above, we slightly change the content of the image (position of the dog, color of the furr, removed necklace) by keeping the overall semantics.
Detection: Statistical Test on Bit Sequences
To detect the watermark:
- Encode the image with the model’s private encoder/tokenizer to get bits.
- Slide a window of length
nover the bits and count how many sequences fall intoGvsR. - Under the null hypothesis “this image is not watermarked,” the number of green sequences behaves like a binomial variable with known mean and variance.
- Compute a z-score and reject the null if
zexceeds a chosen threshold (e.g., corresponding to 1% FPR).
Clean images produce z-scores near 0; BitMark images produce large positive z‑scores. Since our goal is to avoid model collapse by training on our own generated data, we assume the detector (and VQ-VAE) to be private - hence, only the model owner can verify and detect watermarked data.
Quality and Robustness
Using Infinity-2B as the main model (MS-COCO 2014 validation set):
- For practical bias strengths (e.g.,
δ ≤ 2):- FID/KID are similar to non-watermarked images.
- CLIP score (prompt–image alignment) remains nearly unchanged.
- Generation speed overhead is modest (~10% at most).
- Detection is fast (less than a second per image).
BitMark is robust against:
- Common transforms (noise, blur, color jitter, cropping, JPEG, flips).
- Reconstruction-like attacks (encode–decode via Stable Diffusion 2.1’s VAE, regeneration attacks such as CtrlRegen+).
- Strong removal attempts (e.g., “watermarks in the sand”) still leave a clearly detectable signal, at very high computational cost and image degradation within our setting.
Even a custom Bit-Flipper attack—where the attacker knows the encoder, the algorithm, and the exact green/red lists—cannot erase the watermark without severe visual degradation.
Radioactivity: Tracking Your Data Across Models
What is Radioactivity?
Radioactivity is defined here as:
If a model M₂ is trained or fine-tuned on outputs from a watermarked model M₁, then M₂’s outputs still carry a detectable version of M₁’s watermark.
This is crucial for data provenance:
- Model owners can tell whether downstream models have trained on their generated images.
- They can filter out their own generated content when training future model versions to avoid model collapse.
Experiments: Same and Cross Modality
The authors evaluate radioactivity as follows:
- Use Infinity-2B with BitMark to generate watermarked images.
- Train a second model M₂ on these images:
- Case 1: M₂ is another Infinity-2B (same architecture).
- Case 2: M₂ is Stable Diffusion 2.1 (latent diffusion model; different architecture and latent space).
Then they run BitMark’s detector on M₂’s outputs.
Results (TPR at 1% FPR):
- Infinity-2B → Infinity-2B:
- Watermarked M₁ outputs: 100% TPR.
- M₂ outputs: 100% TPR.
- Infinity-2B → Stable Diffusion 2.1:
- M₂ outputs: ~98.9% TPR.
| Training data source | M₂ architecture | TPR @ 1% FPR |
|---|---|---|
| BitMark Infinity-2B | Infinity-2B | 100% |
| BitMark Infinity-2B | Stable Diffusion 2.1 | 98.9% |
| BitMark Infinity-2B | VAR-d30 | 25.6 |
| BitMark Infinity-2B | RAR-XXL | 4.1 |
Despite encoding into a latent space and going through a noising–denoising training process, BitMark’s bit patterns are preserved.
For VAR and RAR, radioactivity decreases. This is most likely because the resolution of VAR- and RAR-generated images is only 256x256, whereas BitMark is always detected at a resolution of 1024x1024 for Infinity-2B, hence huge upscaling is applied here. A more interesting question is why RAR is less radioactive than VAR here. Maybe it is because RAR has a very limited codebook size (i.e., 1024) compared to VAR (i.e., 4096), and further uses fewer tokens per image - which might reduce capabilities to learn the (finegrained) watermark?
How Much Watermarked Data is Needed?
We also vary the fraction of watermarked data used to train M₂:
- Even when only 10% of M₂’s training data is watermarked:
- Detection at 1% FPR is clearly above chance (TPR ~22.7%).
- A Mann–Whitney U test shows the z-score distribution is highly significantly shifted.
- At just 5% watermarked data, the statistical test is already significant.
| % watermarked in M₂ training | TPR @ 1% FPR | Significant |
|---|---|---|
| 10% | 22.7% | ✅ |
| 5% | > 0.5 | ✅ |
In other words:
- You don’t need your data to dominate the training set.
- Even a small fraction of watermarked examples leaves a detectable distributional footprint in M₂’s outputs.
Why This Matters for Preventing Model Collapse
Modern generative models train on:
- Massive, mixed datasets scraped from the internet.
- Growing volumes of model-generated content, often unlabeled.
Without tools like BitMark, it is hard to:
- Know when your own outputs reappear in somebody else’s training set.
- Avoid feeding your own generated data back into later training runs.
BitMark changes that:
- It provides an efficient, in-generation watermark for bitwise autoregressive models.
- Its radioactivity ensures the watermark signal persists through training pipelines.
- Model owners can detect and exclude images derived from their own outputs, mitigating model collapse and enabling principled data governance.
Summary
- BitMark is the first watermarking framework tailored to bitwise autoregressive image models like Infinity and Instella IAR.
- It embeds a watermark by softly biasing bit sequences toward a green list and detects it via a bit-level statistical test.
- BitMark maintains high image quality and low overhead, while being robust to a wide range of attacks.
- BitMark is highly radioactive:
- Models trained on BitMark-watermarked images (even of a different architecture) still produce outputs with a strong, detectable watermark signal.
- This holds even when only a small fraction of the training data is watermarked.
- This radioactivity enables long-term provenance tracking and gives model owners a practical tool to avoid training on their own outputs, helping prevent model collapse.
👉 Read our research paper accepted at NeurIPS 2025.
Bibtex
@inproceedings{
kerner2025bitmark,
title={BitMark: Watermarking Bitwise Autoregressive Image Generative Models},
author={Louis Kerner and Michel Meintz and Bihe Zhao and Franziska Boenisch and Adam Dziedzic},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems},
year={2025},
url={https://openreview.net/forum?id=VSir0FzFnP}
}