Captured by Captions: On Memorization and its Mitigation in Multi-Modal Models
1CISPA Helmholtz Center for Information Security
2Georgia Institute of Technology
Multi-modal models like CLIP are widely used for their state-of-the-art performance on a variety of downstream tasks. But while memorization is well-studied in uni-modal models, its role in multi-modal models is underexplored.
We focus on CLIP, as a representative multi-modal model, and analyze how much it memorizes its training data. We design a new CLIPMem metric to analyze the memorization behavior of CLIP. We observe that the memorization patterns in CLIP fall in between the ones found in supervised learning and self-supervised learning models. We also find that the text encoder in CLIP contributes more memorization than image encoder. Using these insights, we propose mitigation strategies that reduce memorization while simultaneously improving utility – which has not been observed in traditional learning paradigms.
How to measure memorization in CLIP?
CLIP trains an image encoder and a text encoder to map images and captions into a shared latent space. Using contrastive learning, it pulls together matching image-text pairs while pushing apart non-matching pairs. Specifically, it maximizes the similarity score between correct pairs while minimizing it for incorrect pairs.
To measure memorization, we introduce CLIPMem, a new metric that leverages CLIP’s contrastive learning objective. CLIPMem quantifies memorization by measuring similarity scores across two models:
- A model trained on the full dataset.
- A reference model trained on the same dataset but with one image-text pair removed.
If the model aligns the removed pair much more strongly than the reference model, we consider it memorized. Our results show that mislabeled or atypical samples have the highest memorization (Figure 1).

Is the memorization behavior of CLIP more similar to Supervised or Self-Supervised Learning?
In uni-modal models, both supervised learning (SL) and self-supervised learning (SSL) rely on memorization to improve generalization, but they have different memorization behaviors. It’s unclear how these memorization behaviors extend to CLIP, because CLIP entails elements from both – it gets supervisory signals through captions (like SL) but it also learns through the contrastive objective (like SSL).
Our analysis shows that CLIP’s memorization behavior falls between SL and SSL:
✅ Like SL, CLIP memorizes mislabeled or imprecise samples.
✅ Like SSL, CLIP memorizes atypical samples.
✅ Neuron-level analysis shows that earlier layers behave like SL, grouping similar data points together, while later layers behave like SSL, memorizing individual data points (Figure 4).
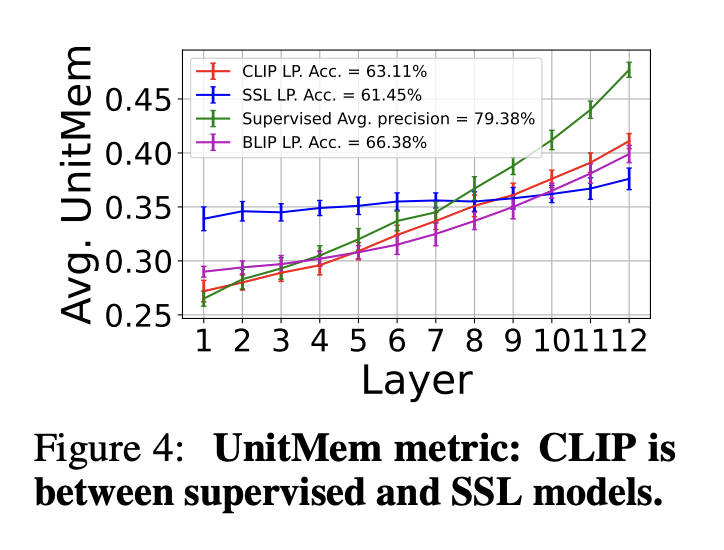
Overall, CLIP doesn’t fully align with the memorization behavior of either SL or SSL, but instead falls somewhere in between.
Is the text encoder or image encoder more responsible for memorization?
CLIP has both the image encoder and the text encoder. But does one contribute more to memorization, or do they do so equally? To figure it out, we applied different augmentation strategies to see their effect on memorization.
Table 1 summarizes the findings:
✅ Text augmentations (multiple captions per image) were more effective at reducing memorization than image augmentations (multiple images per caption) while also improving performance.
✅ Applying both text and image augmentations strikes the best balance – leading to the most reduction in memorization while also improving performance.
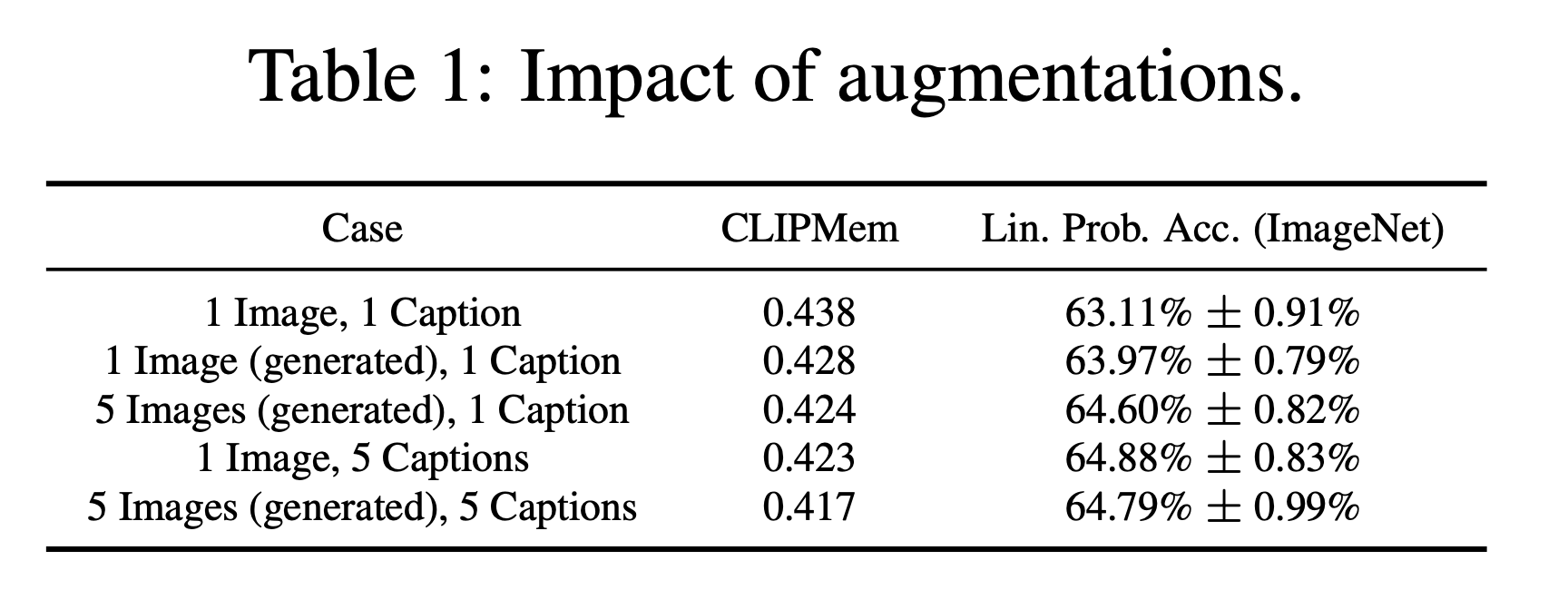
Overall, these results show that the text encoder contributes more to memorization than the image encoder. This means that if we want to mitigate memorization in CLIP, we should focus more on the text domain – like increasing caption diversity or adding noise to text embeddings (detailed in the next section).
So how do we mitigate memorization in CLIP?
Based on our insights, we propose effective mitigation strategies that reduce memorization. A surprising finding from our study is that reducing memorization can actually improve downstream generalization! This is not something that’s typically observed in traditional learning paradigms, where reducing memorization often results in a decrease in utility.
Mitigation strategies:
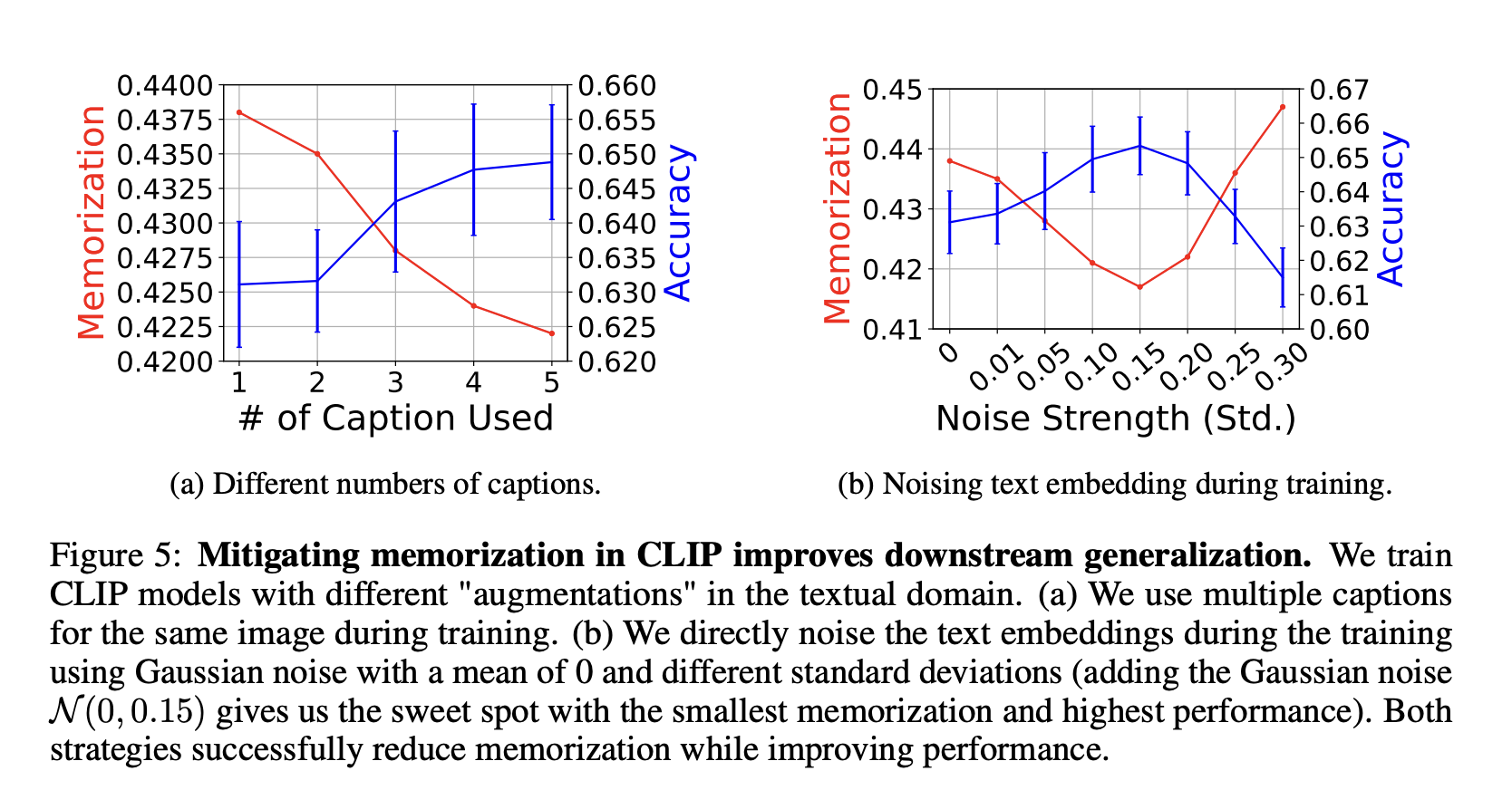
1️⃣ Using multiple captions per image
Our result shows that increasing the number of captions used during training lowers memorization and improves downstream generalization (Figure 5a).
2️⃣ Noising text embedings
To avoid any inherent distribution shifts from augmentations, we propose to perform the “augmentations” directly in the embedding space. Adding small amounts of Gaussian noise to text embeddings during training reduced memorization while improving downstream generalization (Figure 5b).
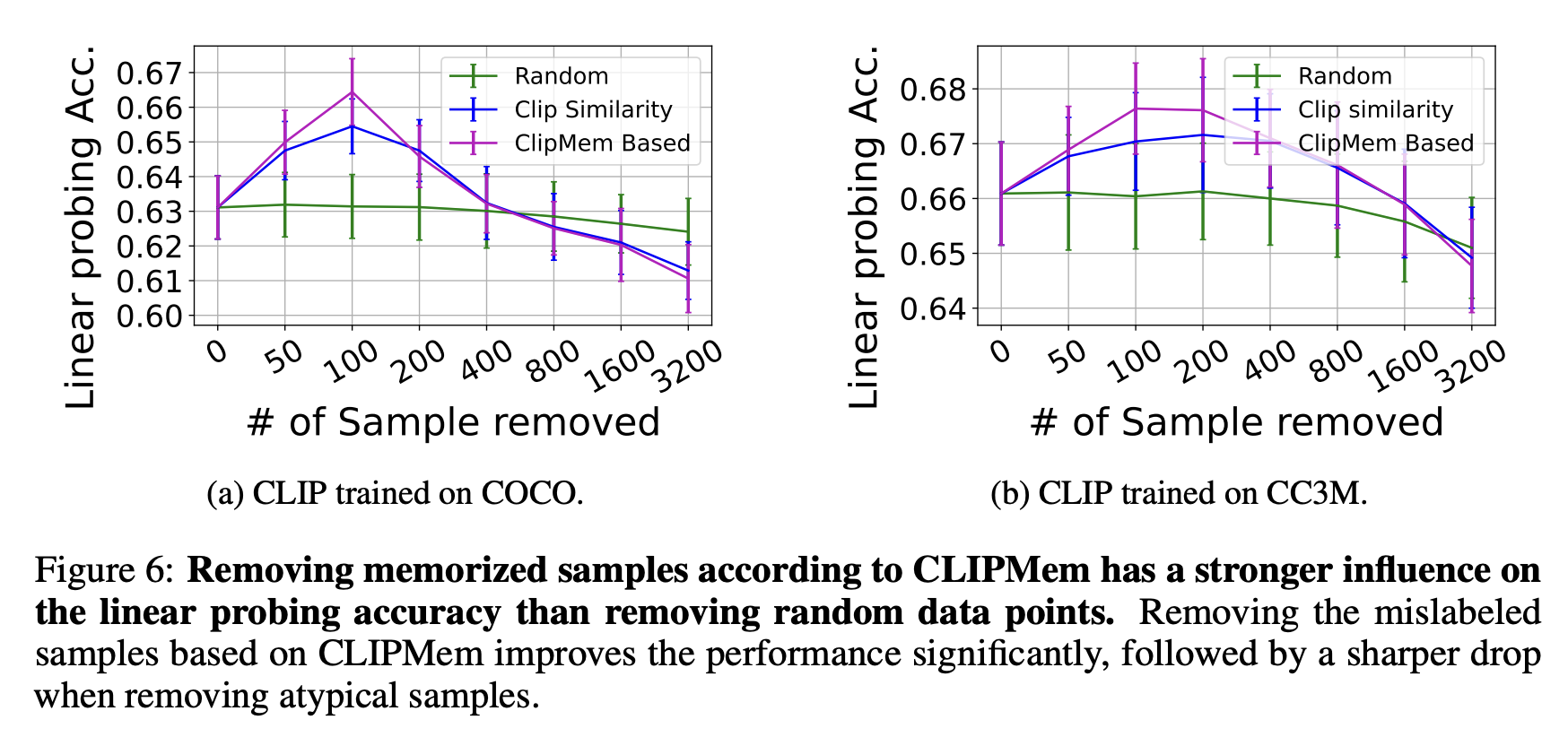
3️⃣ Removing Memorized Samples
By identifying the most memorized samples via CLIPMem and removing them, we actually improved generalization (Figure 6).
Why is this important?
CLIP models are usually trained on large, uncurated datasets sourced from the internet, with no guarantees regarding the correctness of the image-text pairs. By using CLIPMem, we can identify and remove these problematic training examples, making CLIP both more private and more generalizable.
Conclusion
Let’s summarize our findings:
1️⃣ CLIPMem is our new metric that measures memorization in CLIP.
2️⃣ The memorization behavior of CLIP falls between supervised learning and self-supervised learning.
3️⃣ The text encoder is more responsible for memorization than the image encoder.
4️⃣ Effective mitigation strategies include using multiple captions per image, noising text embeddings, and removing memorized samples.
5️⃣ Unlike traditional learning paradigms, reducing memorization in CLIP can actually performance.
👉 Read our: full research paper accepted at ICLR 2025.
Bibtex
@inproceedings{wang2025captured,
title={Captured by Captions: On Memorization and its Mitigation in {CLIP} Models},
author={Wenhao Wang and Adam Dziedzic and Grace C. Kim and Michael Backes and Franziska Boenisch},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=5V0f8igznO}
}