Image AutoRegressive Models Leak More Training Data Than Diffusion Models
1CISPA Helmholtz Center for Information Security
2Warsaw University of Technology
3IDEAS NCBR
*Indicates Equal Contribution
Image AutoRegressive models (IARs) have recently emerged as a powerful alternative to diffusion models (DMs), surpassing them in image generation quality, speed, and scalability. Yet, despite their advantages, the privacy risks of IARs remain completly unexplored. When trained on sensitive or copyrighted data, these models may unintentionally expose training samples, creating major security and ethical concerns.
In this blog post, which is based on our latest research paper, we investigate privacy vulnerabilities in IARs, showing that they exhibit significantly higher privacy risks compared to DMs. We assess IARs’ privacy risks from the three perspectives of membership inference, dataset inference, and memorization, and find that IARs reveal substantially more information about their training data than DMs. Along the way, we also discuss ways to mitigate these risks. Let’s dive in!
Image AutoRegressive Models: A Faster but Riskier Approach
IARs work like language models such as GPT, but instead of words, they generate images using tokens. Just as language tokens represent words or parts of words, image tokens represent some part of an image. This autoregressive approach allows them to scale effectively, resulting in higher quality and faster image generation compared to DMs. However, as we will show, these benefits come with severe privacy trade-offs.
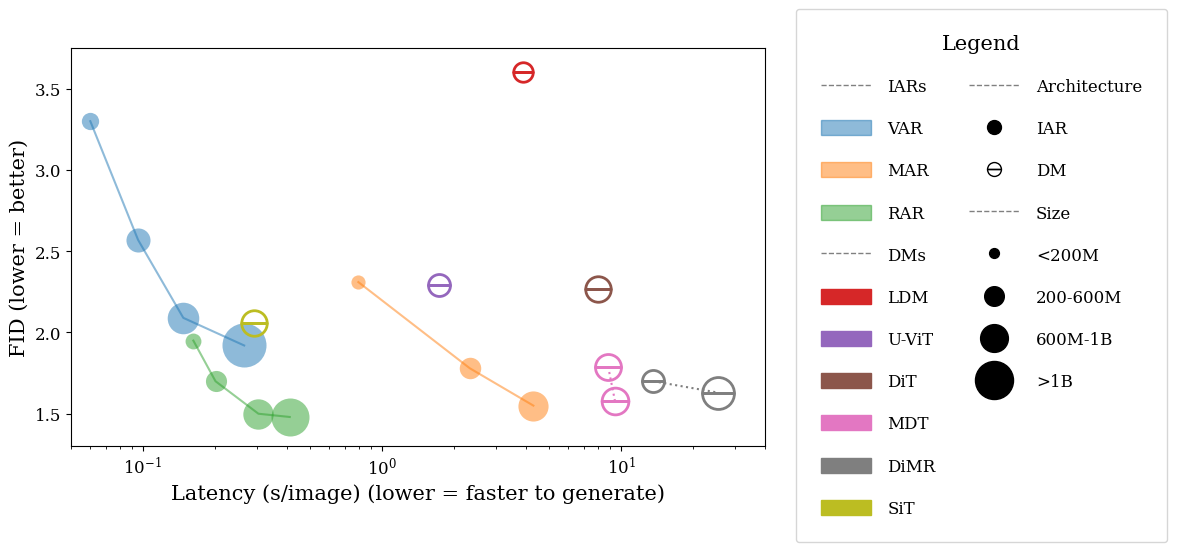
Our evaluations on privacy attacks show that IARs are much more likely to reveal whether a specific image was used in its training and even expose parts of the training data. In fact, the largest IAR models leak entire training images verbatim!
How to Assess Privacy Risks in IARs
To uncover the privacy risks of IARs, we use three attack techniques—refining existing methods and creating new ones from scratch—to measure how much these models expose their training data:
- Membership Inference Attacks (MIA): Determines whether a specific image was used in training.
- Dataset Inference (DI): Detects whether an entire dataset was part of the model’s training set.
- Data Extraction: Extracts full training images from IARs.
These attacks help us quantify how much private data IARs unintentionally reveal compared to DMs.
Membership Inference: IARs vs DMs
The goal of MIAs is to infer whether a specific image was part of the training dataset of a given model. In our study, we first show how MIAs developed against LLMs can be applied to IARs. Then we design a novel MIA approach optimized for IARs by leveraging their classifier-free guidance mechanism.
Our findings are striking: large IARs leak training membership information at much higher rates than diffusion models. The following figure shows the MIA success rates at a strict false positive rate (FPR) of 1%.
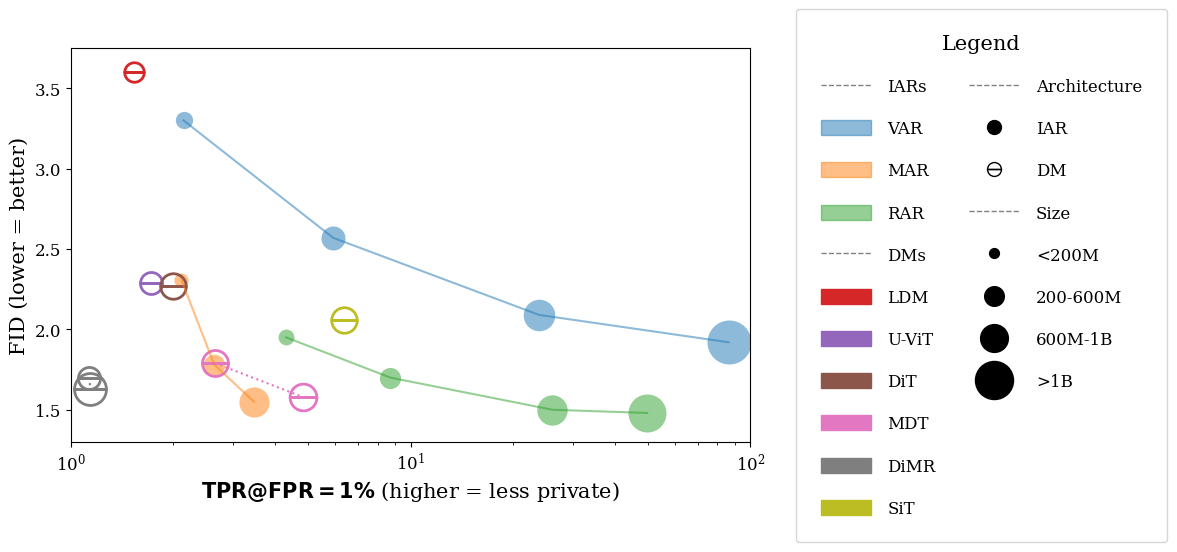
As seen above, VAR-d30, one of the largest IARs, is highly vulnerable to MIAs, with an 86.38% success rate in detecting training images. This is almost 20× higher than the best MIA attack on the least private diffusion model, showing that IARs are inherently more prone to privacy attacks.
Dataset Inference: Detecting If an IAR Was Trained on a Dataset
Dataset Inference (DI) extends MIAs by resolving whether an entire dataset was used in training. This is particularly important for detecting unauthorized usage of private or copyrighted datasets.
We find that IARs require significantly fewer samples for successful DI compared to DMs, meaning they reveal more statistical information about their training datasets. The figure below summarizes the number of samples required to confirm dataset membership.
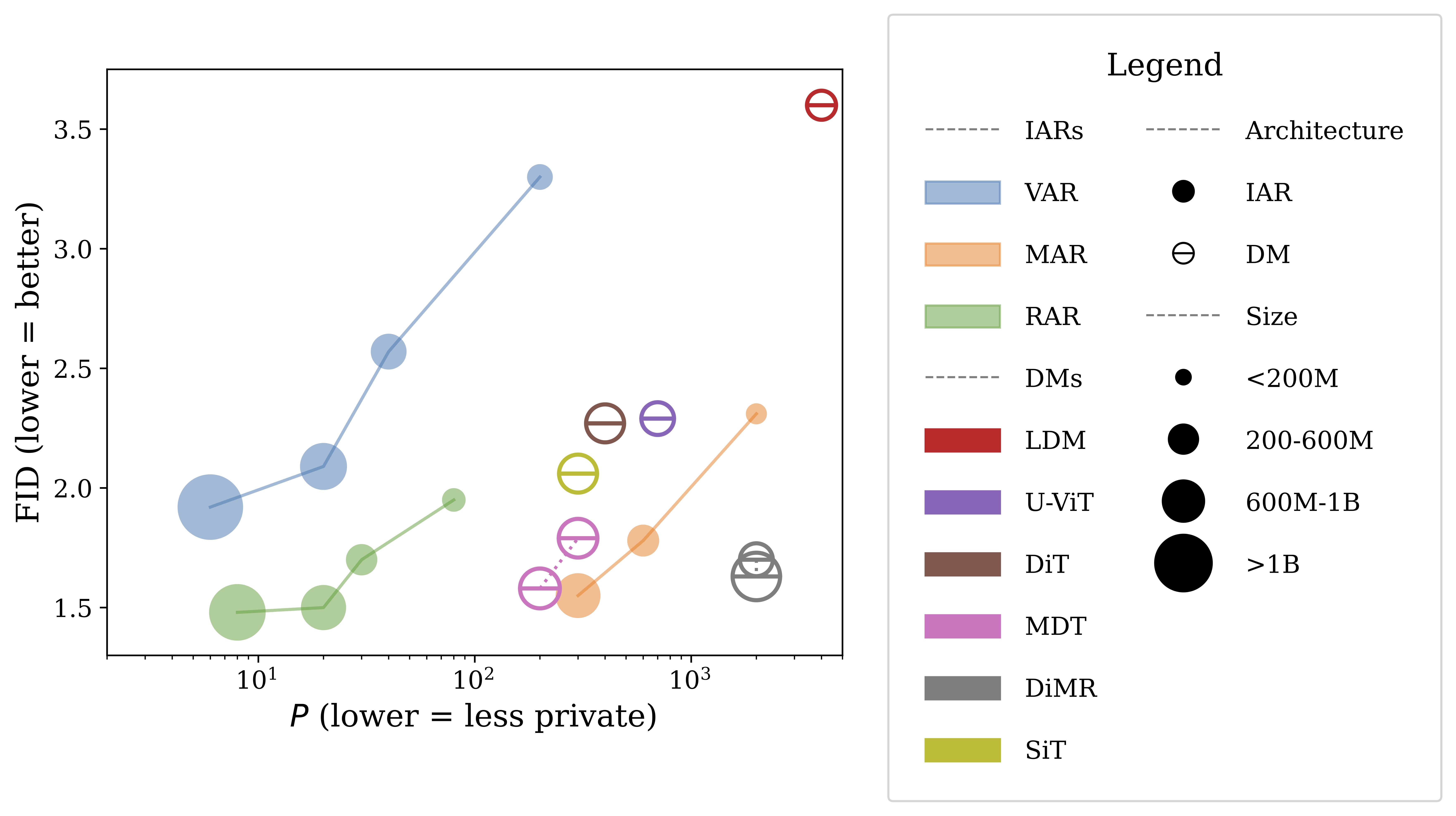
For VAR-d30, only 6 samples are needed to determine whether a dataset was used for training. This is an order-of-magnitude lower than the number required for diffusion models, indicating a much higher privacy leakage.
Extracting Training Images from IARs
Beyond membership and dataset inference, we also explored whether IARs memorize and reproduce entire training images. We developed a data extraction attack that generates high-fidelity reconstructions of training images by prompting the model with a partial input.
We successfully extracted up to 698 verbatim training images from VAR-d30, proving that large IARs memorize and regurgitate data at an alarming rate, making them vulnerable to copyright infringement, privacy violations, and dataset exposure.

The highly successful data extraction from IARs raises major privacy concerns, especially for commercial AI models trained on proprietary datasets.
Privacy vs. Performance: How to Mitigate Privacy Risks in IARs
Our findings reveal a clear privacy-utility trade-off. While IARs outperform Diffusion Models (DMs) in speed and image quality, they suffer from significantly higher privacy leakage. This presents a crucial question: can we achieve strong performance without sacrificing privacy?
Given the severe privacy vulnerabilities of IARs, we explored potential mitigation strategies. Inspired by Differential Privacy (DP) techniques and prior research on language models, we experimented with the following defenses:
1. Adding Noise to Logits
For models like VAR and RAR, we attempted to add small amounts of noise to their logits to obscure membership signals. While this reduced MIA success rates slightly, it also deteriorated image quality, making it an impractical solution.
2. Noising Continuous Tokens in MAR
For MAR, which operates with continuous tokens, we perturbed token values post-sampling. Interestingly, this defense was more effective than logit noise and caused only a minor drop in performance.
3. Leveraging Diffusion Techniques
Our results indicate that MAR is inherently more private than VAR and RAR, likely because it incorporates diffusion-based techniques. This suggests that hybrid IAR-DM approaches could provide a good balance between performance and privacy.
Final Thoughts: Are IARs Too Risky for Deployment?
Our study provides the first comprehensive privacy analysis of Image AutoRegressive Models (IARs). The results are both impressive and alarming:
✅ IARs are faster and more accurate than DMs.
🚨 IARs leak substantially more private data than DMs.
This raises a key concern: Can IARs be deployed safely?
- For non-sensitive applications, IARs offer a powerful and efficient alternative to DMs.
- However, for privacy-sensitive domains (e.g., medical imaging, biometric data, proprietary datasets), IARs pose severe risks unless stronger safeguards are in place.
Conclusions
Let’s summarize our findings:
1️⃣ IARs have much higher privacy leakage than DMs, making them a riskier choice for privacy-sensitive applications.
2️⃣ The larger the IAR, the more it memorizes and leaks training data.
3️⃣ Diffusion-based elements (like those in MAR) reduce privacy leakage, suggesting a potential direction for more private generative models. A promising approach is to synergize diffusion-based and autoregressive techqniques to provide high performance and lower privacy risk.
4️⃣ Existing defenses are insufficient, and new privacy-preserving techniques must be developed before IARs can be safely deployed in sensitive areas.
Where Do We Go from Here?
As IARs continue to evolve, privacy safeguards must become a core focus. Our research shows that adopting techniques from Diffusion Models and differential privacy methods could help mitigate privacy risks.
If you’d like to learn more, check out our full arXiv paper, where we dive deeper into membership inference attacks, dataset inference, and memorization risks in IARs.
👉 Read the full paper: Privacy Attacks on Image AutoRegressive Models
Bibtex
@misc{kowalczuk2025privacyattacksimageautoregressive,
title={Privacy Attacks on Image AutoRegressive Models},
author={Antoni Kowalczuk and Jan Dubiński and Franziska Boenisch and Adam Dziedzic},
year={2025},
eprint={2502.02514},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.02514},
}