Auditing pretraining (Stage 1)
Standard ML auditing applied to the pretrained model $\theta$. The attacker guesses whether target sample $x$ was included in the pretraining set $S$.
Recent work has applied differential privacy (DP) to adapt large language models (LLMs) for sensitive applications, offering theoretical guarantees. However, its practical effectiveness remains unclear, partly due to LLM pretraining, where overlaps and interdependencies with adaptation data can undermine privacy despite DP efforts. To analyze this issue in practice, we investigate privacy risks under DP adaptations in LLMs using state-of-the-art attacks such as robust membership inference (RMIA) and canary data extraction. We benchmark these risks by systematically varying the adaptation data distribution, from exact overlaps with pretraining data, through in-distribution (IID) cases, to entirely out-of-distribution (OOD) examples. Additionally, we evaluate how different adaptation methods and different privacy regimes impact the vulnerability. Our results show that distribution shifts strongly influence privacy vulnerability: the closer the adaptation data is to the pretraining distribution, the higher the practical privacy risk at the same theoretical guarantee, even without direct data overlap. We find that parameter-efficient fine-tuning methods, such as LoRA, achieve the highest empirical privacy protection for OOD data. Our benchmark identifies key factors for achieving practical privacy in DP LLM adaptation, providing actionable insights for deploying customized models in sensitive settings. Looking forward, we propose a structured framework for holistic privacy assessment beyond adaptation privacy, to identify and evaluate risks across the full pretrain-adapt pipeline of LLMs.
We provide the first comprehensive benchmark of empirical privacy risks under DP adaptations of LLMs in the pretrain-adapt paradigm, spanning 6 datasets, 4 adaptation methods, and 7 pretrained models of varying sizes and architectures.
We evaluate a wide range of private adaptation strategies: Full Fine-Tuning, Last-Layer (Head) Fine-Tuning, parameter-efficient LoRA, and Prefix Tuning, all trained with DP-SGD. For a fair comparison, we ensure similar final validation losses across methods and datasets.
Models and pretraining data. We primarily benchmark the Pythia family (70M–1.4B) and GPT-Neo (125M, 1.3B), both trained on the Pile dataset. We also include the fully open-source OLMo 1B and OLMo2 1B models. We focus on the Pythia 1B model as the default model.
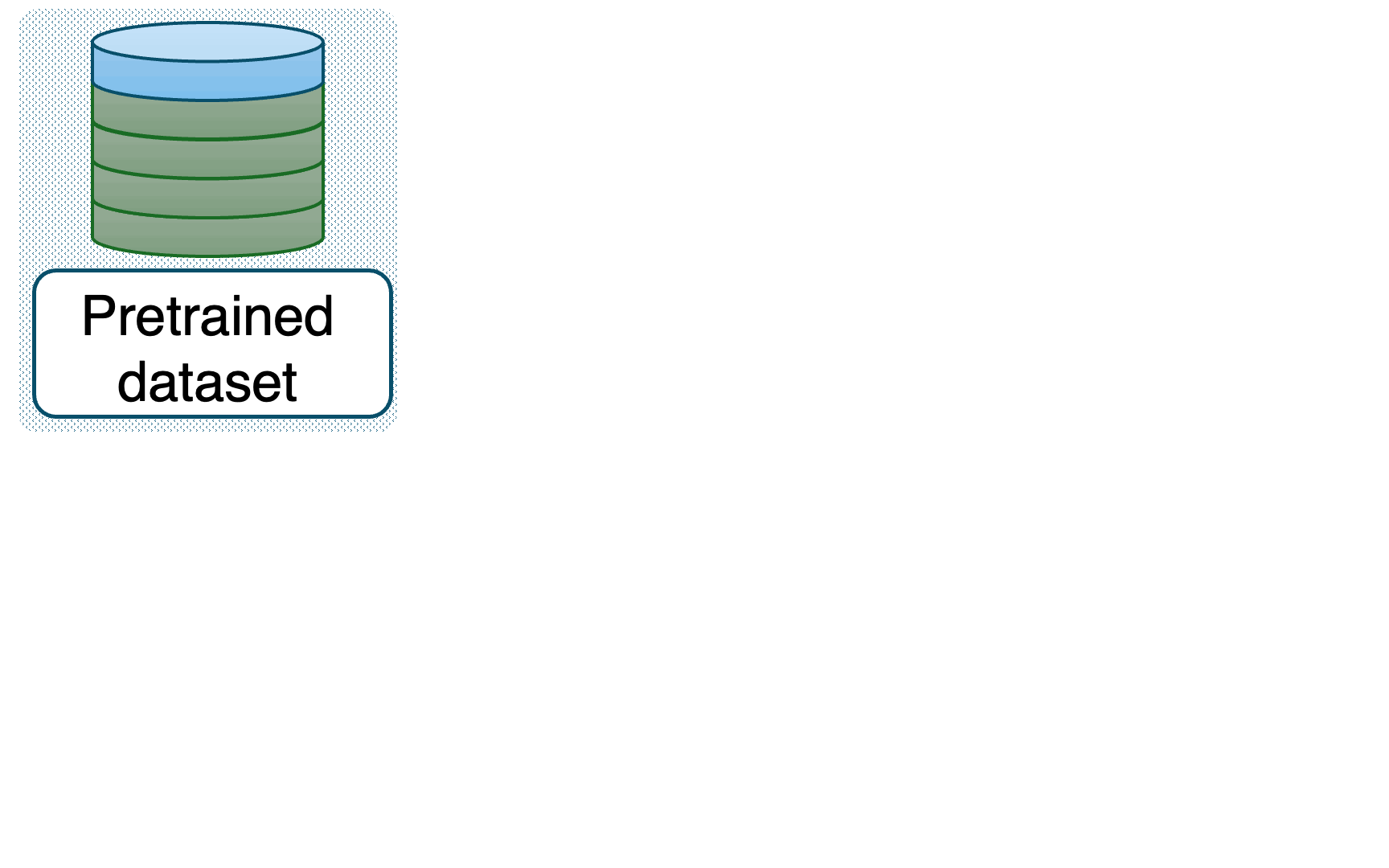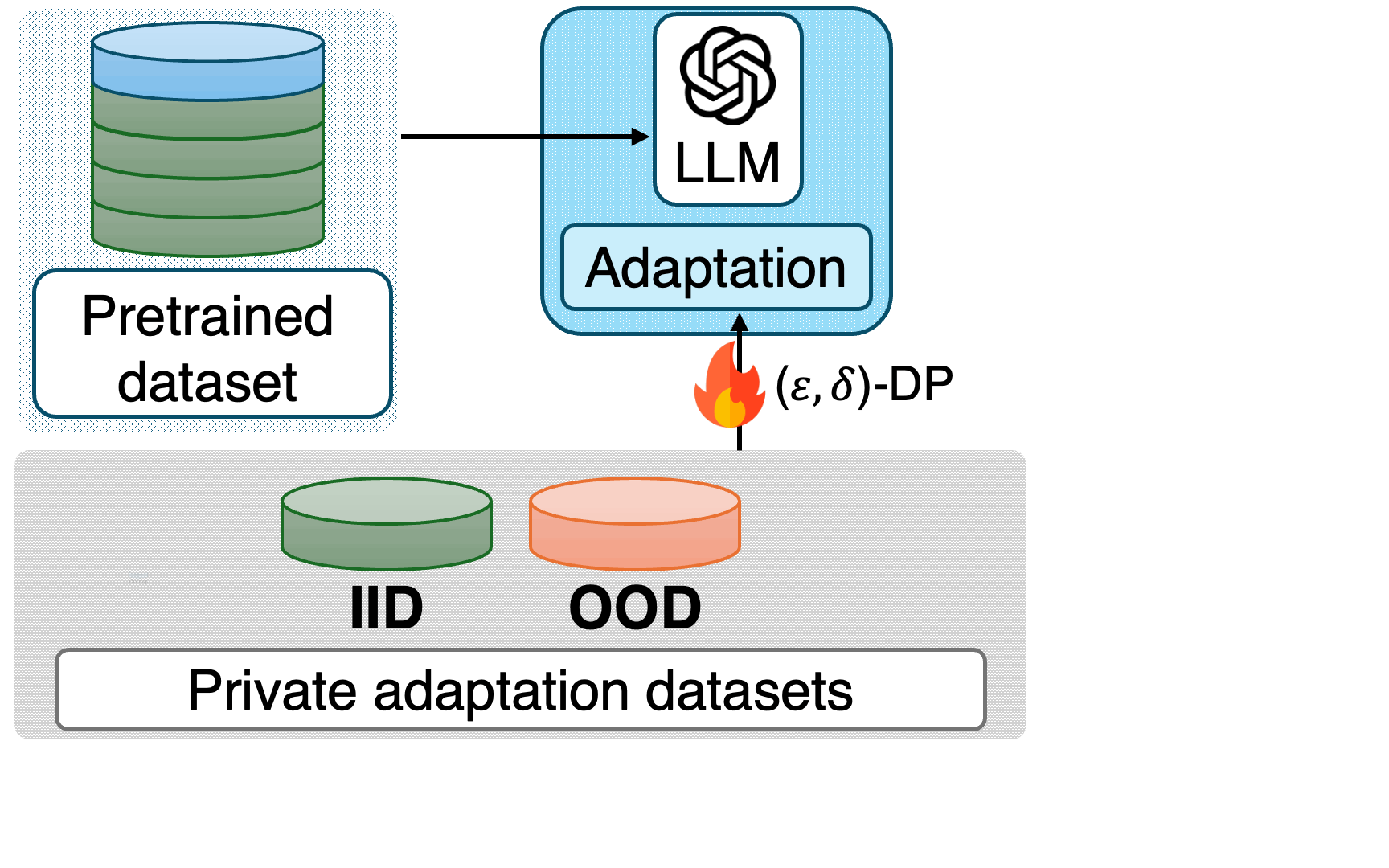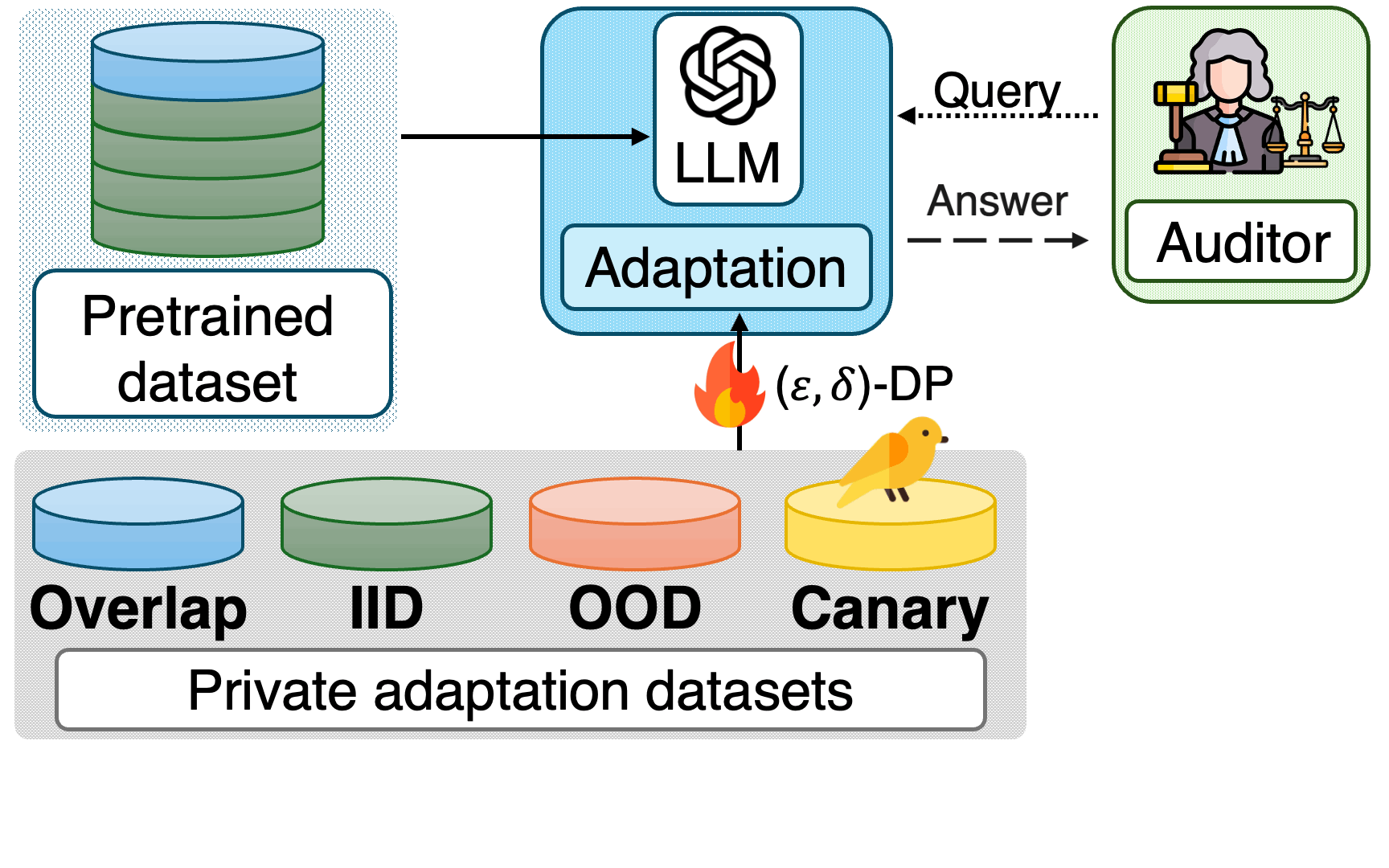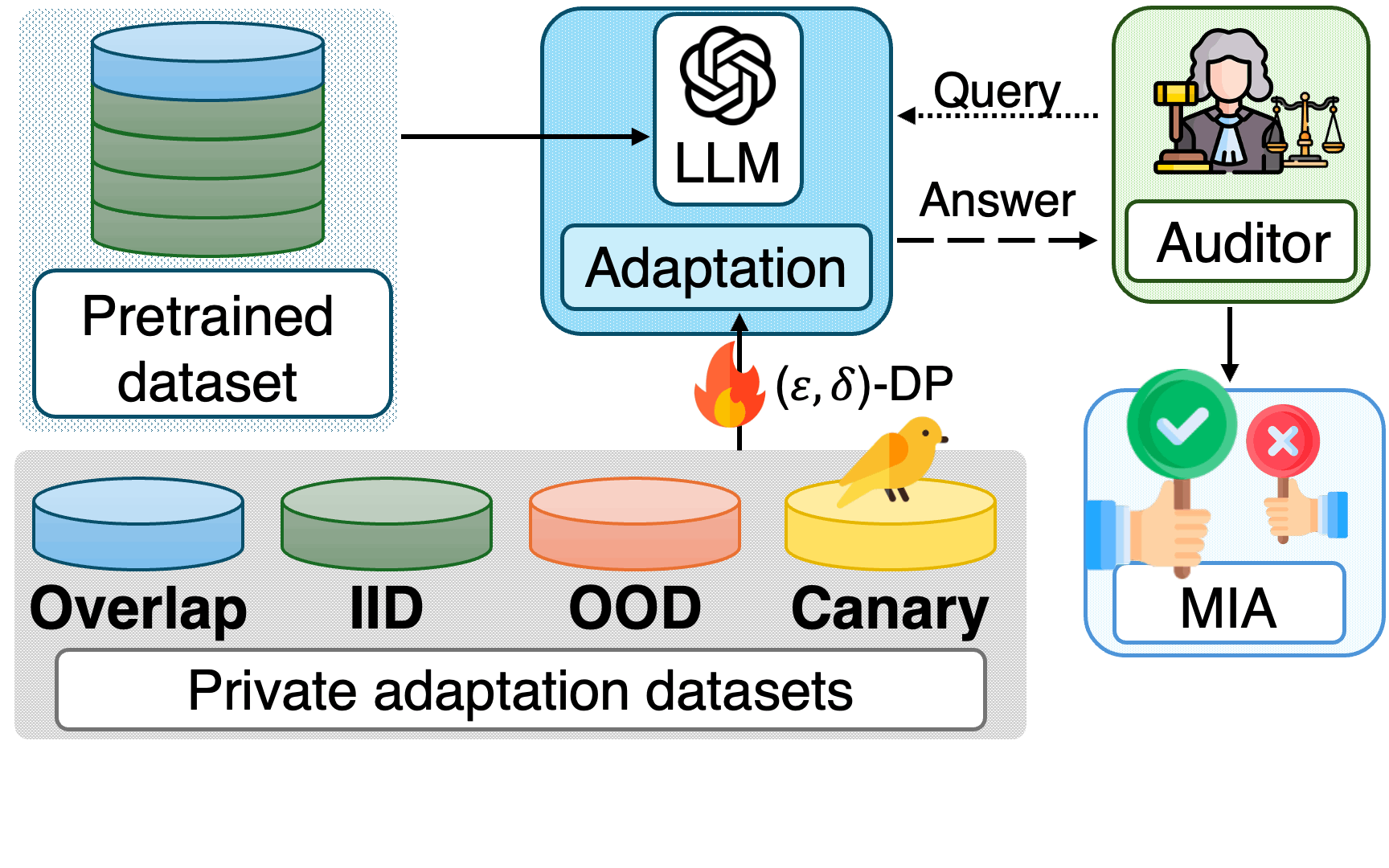
Adaptation datasets. We distinguish three settings:
Attacks. We rely on the state-of-the-art membership inference attack, RMIA (Robust Membership Inference Attack), and complement it with canary data extraction to evaluate more severe forms of leakage.
| Adaptation | Bookcorpus2 IID | Bookcorpus2 Overlap | SAMSum (OOD) | GermanWiki (OOD) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $\varepsilon{=}\infty$ | $\varepsilon{=}8$ | $\varepsilon{=}0.1$ | $\varepsilon{=}\infty$ | $\varepsilon{=}8$ | $\varepsilon{=}0.1$ | $\varepsilon{=}\infty$ | $\varepsilon{=}8$ | $\varepsilon{=}0.1$ | $\varepsilon{=}\infty$ | $\varepsilon{=}8$ | $\varepsilon{=}0.1$ | |
| Prefix Tuning | 1.00 | 0.89 | 0.56 | 1.00 | 0.90 | 0.55 | 1.00 | 0.62 | 0.63 | 1.00 | 0.64 | 0.61 |
| LoRA | 1.00 | 0.70 | 0.52 | 1.00 | 0.69 | 0.53 | 0.86 | 0.69 | 0.50 | 1.00 | 0.59 | 0.66 |
| Full Fine-Tune | 1.00 | 0.75 | 0.77 | 1.00 | 0.75 | 0.76 | 1.00 | 0.82 | 0.62 | 1.00 | 0.71 | 0.55 |
| Head Fine-Tune | 1.00 | 0.72 | 0.73 | 1.00 | 0.72 | 0.72 | 1.00 | 0.98 | 0.62 | 1.00 | 0.76 | 0.70 |
Core finding: Privacy risk scales with distributional closeness to the pretraining data, regardless of whether there is direct overlap. IID validation data, which was never seen during pretraining, leaks as severely as data drawn directly from the pretraining corpus. This pinpoints distributional similarity, not membership overlap, as the primary risk factor.
Concretely, with RMIA (shadow) at $\varepsilon = 8$, average AUC scores on IID data range from 0.70–0.90, compared to 0.63–0.87 on OOD data. Under no-privacy ($\varepsilon = \infty$) all IID settings achieve AUC = 1.00, confirming that IID data is trivially exposed before any DP protection is even applied. The effect is most pronounced for PEFT methods like LoRA, where the gap between IID and OOD leakage is especially clear.
This finding empirically confirms the theoretical concern of Tramèr et al. (2022): privately adapting an LLM that was pretrained on similar data does not provide the privacy protection that formal DP guarantees might suggest.
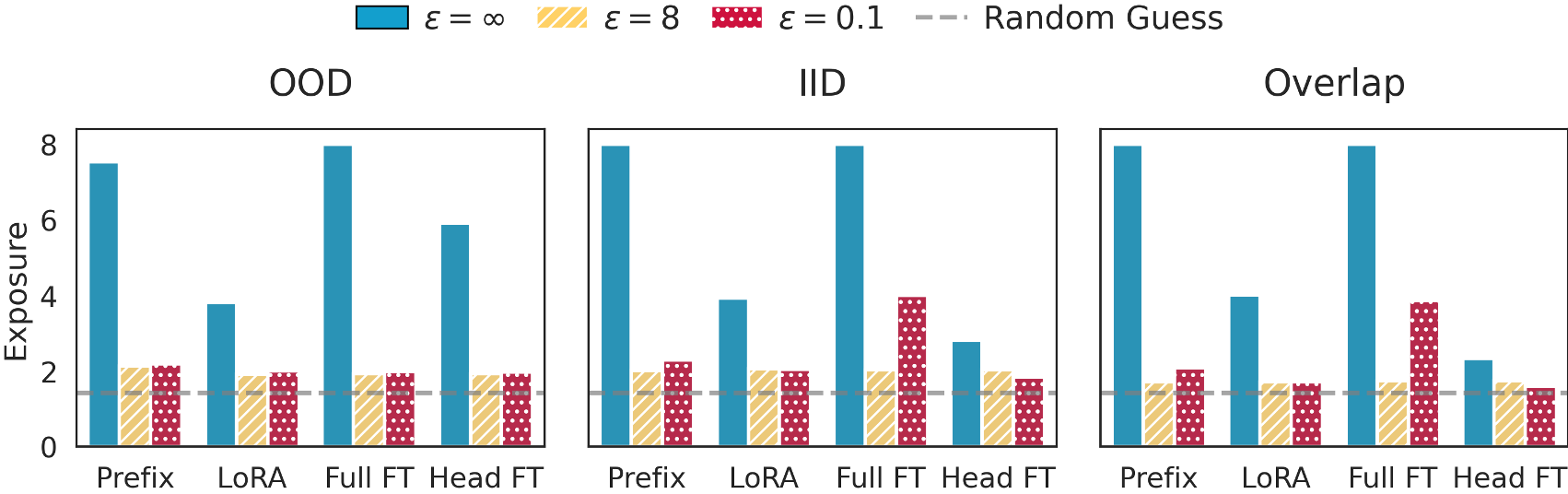
Membership inference. Across privacy regimes and datasets, LoRA consistently achieves the lowest AUC. At $\varepsilon = 0.1$ on IID data, LoRA reaches AUC = 0.52, near random guessing, while Full Fine-Tune and Head Fine-Tune remain above 0.70. This gap persists across datasets and attack configurations, making LoRA the de-facto recommended method when empirical privacy is a concern.
The relative ordering of methods depends on the data regime. For OOD data at moderate privacy ($\varepsilon = 8$), Head Fine-Tune becomes the most vulnerable (AUC up to 0.98 on SAMSum), while LoRA stays closest to 0.5. Full Fine-Tune occupies the middle ground.
Data extraction. Against canary extraction attacks, Prefix Tuning is the most vulnerable adaptation method. LoRA and Head Fine-Tune both exhibit strong resistance against extraction regardless of canary type, privacy budget, or data distribution. At $\varepsilon = 0.1$, all methods show exposure close to the random-guessing baseline (≈ 1.44), confirming that tight DP constraints do suppress extraction risk. The adversarial prefix is the dominant source of leakage; the interaction between prefix and the canary sample itself plays a secondary role.
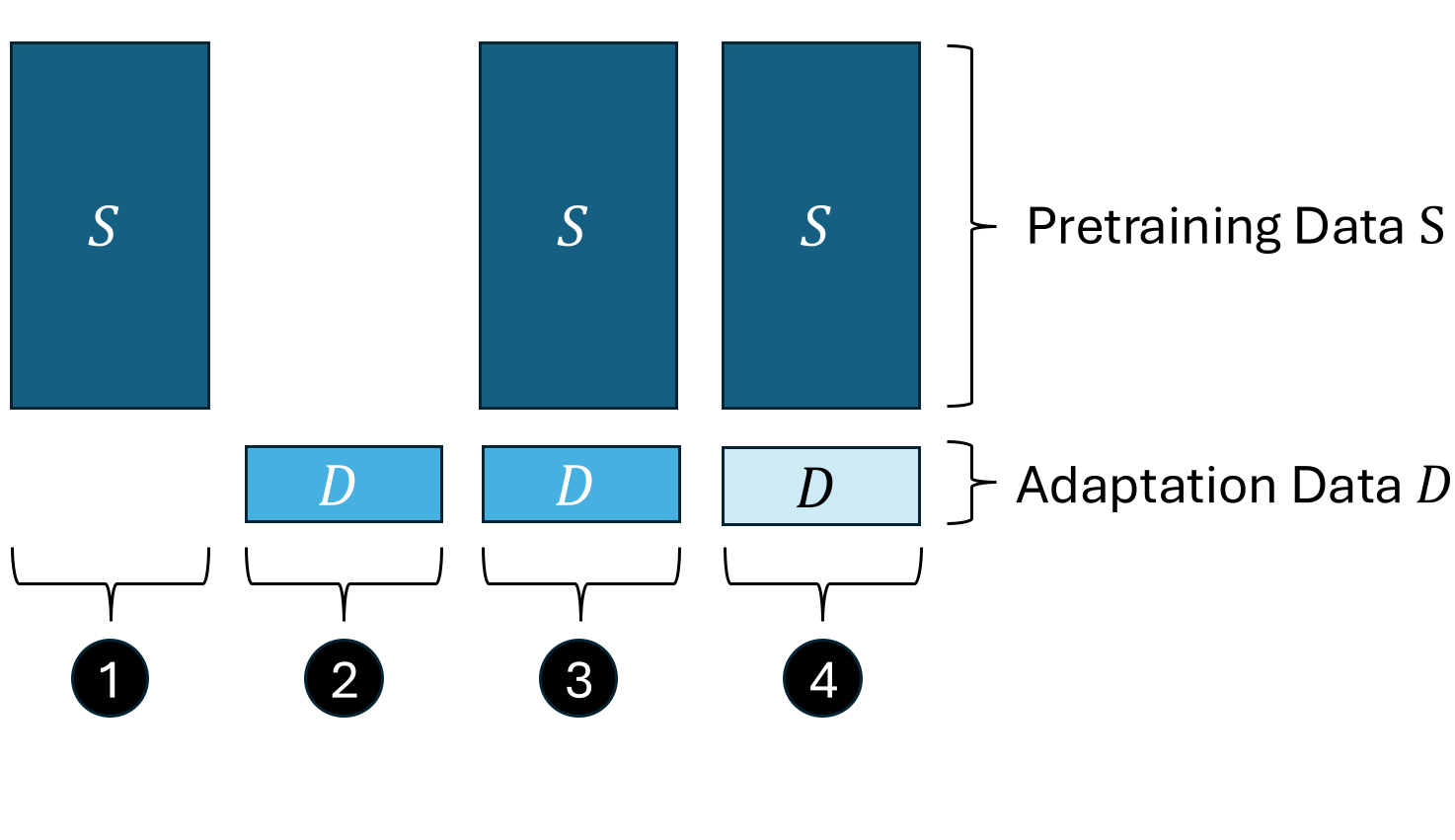
Examining pretraining and adaptation privacy in isolation yields a dangerously incomplete picture. The strong interdependence between these stages demands a unified view. We formalize the pretrain-adapt adversarial game and identify four distinct auditing stages, each with its own threat model and membership inference hypothesis:
Formalizing these stages enables a systematic framework for privacy measurement across the full pipeline, supports structured reasoning about what privacy risks each method introduces, and motivates future work on joint auditing tools that match the complexity of modern LLM deployments.
Our benchmark surfaces actionable guidelines for practitioners deploying DP-adapted LLMs in sensitive settings:
We benchmark the practical privacy risks that arise under DP adaptations of LLMs within the pretrain-adapt paradigm. Our comprehensive empirical analysis confirms the theoretical concern that pretraining significantly amplifies the privacy risks associated with the adaptation data.
@inproceedings{
marek2026benchmarking,
title={Benchmarking Empirical Privacy Protection for Adaptations of Large Language Models},
author={Bart{\l}omiej Marek and Lorenzo Rossi and Vincent Hanke and Xun Wang and Michael Backes and Franziska Boenisch and Adam Dziedzic},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=jY7fAo9rfK}
}